Date: Tue, 5 Jan 2021 00:53:54 -0500
During the recent SG16 reviews of P2093 <https://wg21.link/p2093> during
the 2020-11-11
<https://github.com/sg16-unicode/sg16-meetings#november-11th-2020> and
2020-12-09
<https://github.com/sg16-unicode/sg16-meetings#december-9th-2020>
telecons and on the SG16 mailing list (here
<https://lists.isocpp.org/sg16/2020/11/1941.php>, continued here
<https://lists.isocpp.org/sg16/2020/12/1950.php>), I expressed a
preference for the proposed std::print() to transcode as necessary to
match the system/run-time encoding when output is not directly connected
to a terminal/console and that, on Windows, this would mean converting
output to match the Active Code Page (ACP). The following tests
indicate that the situation is more complicated on Windows.
My preference for matching the system/run-time encoding is motivated by
process interactions as occurs in command pipe lines. The following
experiments were conducted to investigate current behavior and existing
practice.
All code examples were compiled using the Microsoft Visual C++ 2019 x64
compiler. All experiments were performed on a Windows 10 system
configured with region system locale settings set to "English (United
States)" (ACP as Windows-1252, console encoding default as CP437). Note
that these experiments are not concerned with the proper display of text
in the Windows console, but rather with encoding expectations in piped text.
Experiment 1:
The first thing I tried was writing a simple program that writes "téxt"
in each of the UTF-8, Windows-1252, and CP437 encodings and then
checking to see which encoding was matched by the Windows find and
findstr utilities. The following code was saved as print-text.cpp and
compiled with cl /Feprint-text.cpp /EHsc print-text.cpp.
#include <iostream>
int main() {
std::cout << "UTF-8: t\xC3\xA9xt\n";
std::cout << "W1252: t\xE9xt\n";
std::cout << "CP437: t\x82xt\n";
}
Here are the results with the console encoding set to the default
CP437. Both find and findstr match the CP437 encoded text.
>chcp
Active code page: 437
>print-text | find "téxt"
CP437: téxt
C:\cygwin\home\Tom\test\test-console>print-text | findstr "téxt"
CP437: téxt
Changing the console encoding to Windows-1252 produced the first
surprising result. find now matched the Windows-1252 encoded text, but
findstr continued to match the CP437 text. The incorrect display of the
CP437 encoded text for the findstr case is expected due to the console
encoding change.
>chcp 1252
Active code page: 1252
>print-text | find "téxt"
W1252: téxt
>print-text | findstr "téxt"
CP437: t‚xt
Changing the console encoding to UTF-8 produced a similar result.
>chcp 65001
Active code page: 65001
>print-text | find "téxt"
UTF-8: téxt
>print-text | findstr "téxt"
CP437: txt
Conclusions:
1. The Windows find utility expects text encoded in the ACP.
2. The Windows findstr utility behavior is curious. The "Character
limits for command line parameters - Extended ASCII transformation"
section of this Stack Overflow answer
<https://stackoverflow.com/a/8844873/11634221> may explain the
findstr behavior (I'm not sure), strange as it is.
Experiment 2:
The previous experiment probed what encoding is expected for input by
the find and findstr utilities. This next one probed what encoding is
used when producing output that will be input to another process.
Consider a utility that displays a message provided either on the
command line or via stdin. The following source code implements such a
utility:
#include <windows.h>
#include <iostream>
#include <string>
void usage(const char *program_name) {
std::cerr << "Usage: " << program_name << " [<message>]\n";
}
int main(int argc, char **argv) {
if (argc > 2) {
usage(argv[0]);
return 1;
}
std::string message_text;
if (argc > 1) {
message_text = argv[1];
} else {
std::getline(std::cin, message_text);
}
MessageBox(NULL, message_text.c_str(), "Message", MB_OK);
}
This code was saved as display-message.cpp and compiled with cl
/Fedisplay-message.exe /EHsc display-message.cpp user32.lib to produce
an executable named display-message.exe. Note that the source code
contains no non-ASCII characters, so compilation with the /utf-8 option
would currently have no effect.
The console encoding was reset to the default of CP437 before running
the utility.
>chcp 437
Active code page: 437
The utility was then run with the following two commands with the
expectation that each would produce the same observed behavior.
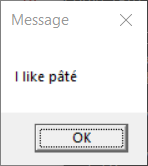
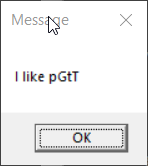
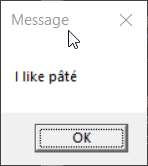
> display-message "I like pâté"
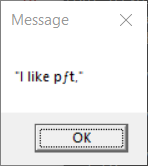
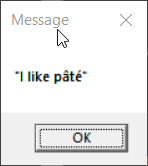
> echo "I like pâté" | display-message
I was surprised to find that different behavior was exhibited.
In the first case, the message was displayed as expected. What happens
in this case is that a UTF-16 encoded command line is constructed and
provided to the new process. That command line is then transcoded
(presumably by mainCRTStartup()) to the ACP as part of preparing the
parsed arguments passed to main(). The result is an ACP encoded message
being passed to MessageBox() (which expects ACP encoded text).
In the second case, the non-ASCII characters are not displayed as
expected. What appears to happen in this case is that the Unicode text
entered at the console is transcoded to the console encoding when the
output is redirected. The result is that the program receives console
encoded input in stdin which is then passed to MessageBox() (which
expects ACP encoded text).
In order to validate that the use of the console encoding was not
somehow specific to the echo command, I retried the experiment using dir
and files named résumé.txt and þeta.txt (þ lacks representation in
CP437). For both files, dir was able to display the correct name to the
console regardless of the whether the current console encoding was CP437
or Windows-1252 (dir appears to use the Unicode console APIs when output
is directed directly to the console; analogous to what is proposed in
P2093 <https://wg21.link/p2093>). However, when the output was piped to
display-message, the output was produced in the console encoding
analogous to echo above./
/
Conclusions:
1. At least some programs produce output encoded as the console
encoding. This contrasts with the prior experiment.
2. Programs on Windows (that use the standard main() entry point)
should expect differently encoded text (by default) for input
received on the command line vs input received from piped text.
Experiment 3:
The previous experiment prompted me to question what encoding is used
for .bat files. To answer that question, I created CP437 and
Windows-1252 encoded .bat files with the two commands from the prior
experiment:
@echo off
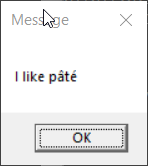
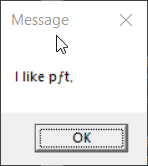
display-message "I like pâté"
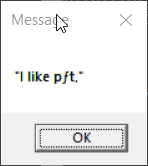
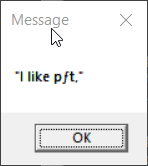
echo "I like pâté" | display-message
Each of these was then run with matched and mismatched console encodings.
>chcp 437
Active code page: 437
>test-display-message-cp437.bat
>test-display-message-w1252.bat
>chcp 1252
Active code page: 1252
>test-display-message-cp437.bat
>test-display-message-w1252.bat
Conclusions:
1. The only case that reproduced the behavior of the prior experiment
is the one where the console encoding and the encoding of the .bat
file were both CP437.
2. The only case that correctly reproduced the message for both
invocations of display-message is the one in which the console
encoding, ACP, and .bat file encoding were all Windows-1252. Every
other case involves mojibake in some way.
Overall Conclusions
1. There is no one encoding that can be assumed as the lingua franca of
process pipelines on Windows. Some utilities expect the ACP, some
utilities produce output in the console encoding, some utilities are
hopelessly broken.
2. Any encoding choice made for std::print() will be incorrect for
reasonable use cases.
3. I don't know of any programmatic method for determining what
encoding the other end of a pipe produces/expects.
4. In general, the programmer does not have sufficient information to
choose the right encoding unless additional information is provided
at run-time.
5. The only hope for truly fixing this mess is a transition to UTF-8 as
the ACP and console encoding.
6. Command line arguments as received via main() in programs compiled
with the Microsoft Visual C++ compiler are encoded in the ACP.
7. In general, mixing input received via standard file streams and the
command line results in mojibake; writing command line arguments to
standard file streams likely results in mojibake as well.
8. We *could* specify a new portable entry point (a new main()
signature or an alternative to main()) that provides UTF-8 encoded
command line arguments (presumably with substitution characters in
place of non-transcodeable content).
Tom.
the 2020-11-11
<https://github.com/sg16-unicode/sg16-meetings#november-11th-2020> and
2020-12-09
<https://github.com/sg16-unicode/sg16-meetings#december-9th-2020>
telecons and on the SG16 mailing list (here
<https://lists.isocpp.org/sg16/2020/11/1941.php>, continued here
<https://lists.isocpp.org/sg16/2020/12/1950.php>), I expressed a
preference for the proposed std::print() to transcode as necessary to
match the system/run-time encoding when output is not directly connected
to a terminal/console and that, on Windows, this would mean converting
output to match the Active Code Page (ACP). The following tests
indicate that the situation is more complicated on Windows.
My preference for matching the system/run-time encoding is motivated by
process interactions as occurs in command pipe lines. The following
experiments were conducted to investigate current behavior and existing
practice.
All code examples were compiled using the Microsoft Visual C++ 2019 x64
compiler. All experiments were performed on a Windows 10 system
configured with region system locale settings set to "English (United
States)" (ACP as Windows-1252, console encoding default as CP437). Note
that these experiments are not concerned with the proper display of text
in the Windows console, but rather with encoding expectations in piped text.
Experiment 1:
The first thing I tried was writing a simple program that writes "téxt"
in each of the UTF-8, Windows-1252, and CP437 encodings and then
checking to see which encoding was matched by the Windows find and
findstr utilities. The following code was saved as print-text.cpp and
compiled with cl /Feprint-text.cpp /EHsc print-text.cpp.
#include <iostream>
int main() {
std::cout << "UTF-8: t\xC3\xA9xt\n";
std::cout << "W1252: t\xE9xt\n";
std::cout << "CP437: t\x82xt\n";
}
Here are the results with the console encoding set to the default
CP437. Both find and findstr match the CP437 encoded text.
>chcp
Active code page: 437
>print-text | find "téxt"
CP437: téxt
C:\cygwin\home\Tom\test\test-console>print-text | findstr "téxt"
CP437: téxt
Changing the console encoding to Windows-1252 produced the first
surprising result. find now matched the Windows-1252 encoded text, but
findstr continued to match the CP437 text. The incorrect display of the
CP437 encoded text for the findstr case is expected due to the console
encoding change.
>chcp 1252
Active code page: 1252
>print-text | find "téxt"
W1252: téxt
>print-text | findstr "téxt"
CP437: t‚xt
Changing the console encoding to UTF-8 produced a similar result.
>chcp 65001
Active code page: 65001
>print-text | find "téxt"
UTF-8: téxt
>print-text | findstr "téxt"
CP437: txt
Conclusions:
1. The Windows find utility expects text encoded in the ACP.
2. The Windows findstr utility behavior is curious. The "Character
limits for command line parameters - Extended ASCII transformation"
section of this Stack Overflow answer
<https://stackoverflow.com/a/8844873/11634221> may explain the
findstr behavior (I'm not sure), strange as it is.
Experiment 2:
The previous experiment probed what encoding is expected for input by
the find and findstr utilities. This next one probed what encoding is
used when producing output that will be input to another process.
Consider a utility that displays a message provided either on the
command line or via stdin. The following source code implements such a
utility:
#include <windows.h>
#include <iostream>
#include <string>
void usage(const char *program_name) {
std::cerr << "Usage: " << program_name << " [<message>]\n";
}
int main(int argc, char **argv) {
if (argc > 2) {
usage(argv[0]);
return 1;
}
std::string message_text;
if (argc > 1) {
message_text = argv[1];
} else {
std::getline(std::cin, message_text);
}
MessageBox(NULL, message_text.c_str(), "Message", MB_OK);
}
This code was saved as display-message.cpp and compiled with cl
/Fedisplay-message.exe /EHsc display-message.cpp user32.lib to produce
an executable named display-message.exe. Note that the source code
contains no non-ASCII characters, so compilation with the /utf-8 option
would currently have no effect.
The console encoding was reset to the default of CP437 before running
the utility.
>chcp 437
Active code page: 437
The utility was then run with the following two commands with the
expectation that each would produce the same observed behavior.
> display-message "I like pâté"
> echo "I like pâté" | display-message
I was surprised to find that different behavior was exhibited.
In the first case, the message was displayed as expected. What happens
in this case is that a UTF-16 encoded command line is constructed and
provided to the new process. That command line is then transcoded
(presumably by mainCRTStartup()) to the ACP as part of preparing the
parsed arguments passed to main(). The result is an ACP encoded message
being passed to MessageBox() (which expects ACP encoded text).
In the second case, the non-ASCII characters are not displayed as
expected. What appears to happen in this case is that the Unicode text
entered at the console is transcoded to the console encoding when the
output is redirected. The result is that the program receives console
encoded input in stdin which is then passed to MessageBox() (which
expects ACP encoded text).
In order to validate that the use of the console encoding was not
somehow specific to the echo command, I retried the experiment using dir
and files named résumé.txt and þeta.txt (þ lacks representation in
CP437). For both files, dir was able to display the correct name to the
console regardless of the whether the current console encoding was CP437
or Windows-1252 (dir appears to use the Unicode console APIs when output
is directed directly to the console; analogous to what is proposed in
P2093 <https://wg21.link/p2093>). However, when the output was piped to
display-message, the output was produced in the console encoding
analogous to echo above./
/
Conclusions:
1. At least some programs produce output encoded as the console
encoding. This contrasts with the prior experiment.
2. Programs on Windows (that use the standard main() entry point)
should expect differently encoded text (by default) for input
received on the command line vs input received from piped text.
Experiment 3:
The previous experiment prompted me to question what encoding is used
for .bat files. To answer that question, I created CP437 and
Windows-1252 encoded .bat files with the two commands from the prior
experiment:
@echo off
display-message "I like pâté"
echo "I like pâté" | display-message
Each of these was then run with matched and mismatched console encodings.
>chcp 437
Active code page: 437
>test-display-message-cp437.bat
>test-display-message-w1252.bat
>chcp 1252
Active code page: 1252
>test-display-message-cp437.bat
>test-display-message-w1252.bat
Conclusions:
1. The only case that reproduced the behavior of the prior experiment
is the one where the console encoding and the encoding of the .bat
file were both CP437.
2. The only case that correctly reproduced the message for both
invocations of display-message is the one in which the console
encoding, ACP, and .bat file encoding were all Windows-1252. Every
other case involves mojibake in some way.
Overall Conclusions
1. There is no one encoding that can be assumed as the lingua franca of
process pipelines on Windows. Some utilities expect the ACP, some
utilities produce output in the console encoding, some utilities are
hopelessly broken.
2. Any encoding choice made for std::print() will be incorrect for
reasonable use cases.
3. I don't know of any programmatic method for determining what
encoding the other end of a pipe produces/expects.
4. In general, the programmer does not have sufficient information to
choose the right encoding unless additional information is provided
at run-time.
5. The only hope for truly fixing this mess is a transition to UTF-8 as
the ACP and console encoding.
6. Command line arguments as received via main() in programs compiled
with the Microsoft Visual C++ compiler are encoded in the ACP.
7. In general, mixing input received via standard file streams and the
command line results in mojibake; writing command line arguments to
standard file streams likely results in mojibake as well.
8. We *could* specify a new portable entry point (a new main()
signature or an alternative to main()) that provides UTF-8 encoded
command line arguments (presumably with substitution characters in
place of non-transcodeable content).
Tom.

Received on 2021-01-04 23:53:58