Date: Wed, 23 Oct 2024 11:05:08 -0700
Dear Unicoders,
I wanted to follow up on our recent telecon, as I realized that I may not
have fully conveyed important issues regarding the proposed thread name
facility. Specifically, its reliance on the C locale being fundamentally
incompatible with much of the standard C++ library and even the underlying
system APIs. To illustrate these concerns, I conducted a series of
experiments, summarized below:
1. Using C locale is incompatible with std::format, std::print and all
formatters where literal encoding is assumed throughout. Even the most
trivial use case similar to the one discussed last time doesn't work:
constexpr int num_threads = 2;
std::thread t[num_threads];
for (int i = 0; i < num_threads; ++i) {
t[i] = std::thread([] {
do_work();
});
set_thread_name_c_locale(t[i].native_handle(), std::format("нітка{}",
i).c_str());
}
where set_thread_name_c_locale is defined as follows:
void set_thread_name_c_locale(HANDLE h, const char* name) {
wchar_t buf[256];
mbstowcs(buf, name, 256);
SetThreadDescription(h, buf);
}
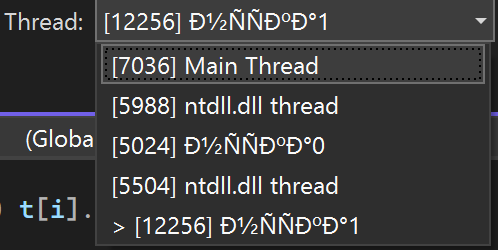
This gives mojibake on Windows with Belarusian localization. Here's an
output with literal encoding UTF-8 (although mojibake happens in non-UTF-8
case as well):
[image: image.png]
2. The proposed facility is inconsistent with std::to_string, which does
not use any locales:
set_thread_name_c_locale(t[i].native_handle(), ("нітка" +
std::to_string(i)).c_str());
Integral overloads never used locales and floating-point overloads won't
use locales as of C++26 and were broken previously anyway.
3. The facility is incompatible with iostreams, as they use the C++ locale
imbued in the stream for non-text components:
std::ostringstream os;
os << "нітка" << i;
set_thread_name_c_locale(t[i].native_handle(), os.str().c_str());
4. It is even incompatible with sprintf in common cases:
char name[16];
sprintf(name, "нітка%d", i);
set_thread_name_c_locale(t[i].native_handle(), name);
Note that sprintf doesn't use the C locale here. It was pointed out to me
by one of the C standard library maintainers when I was writing the
std::to_string paper and allowed us to completely eliminate the use of
locales in this API which was a major improvement.
All of those examples give incorrect thread name output shown earlier,
contrary to some information circulated during the previous discussion.
It would be very unfortunate to standardize a new facility that treats
non-English speaking C++ users as “second-class citizens" giving unusable
output / mojibake even in the most basic cases.
Neither pthread_setname_np nor pthread_getname_np assume the C locale
encoding. For example, quoting
https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html:
The thread name is a string of length 31 bytes or less, UTF-8 encoded.
This means that the POSIX implementation in P2019R7 is actually incorrect
and doesn’t match the wording. Making it match the wording may require
transcoding from the locale encoding on POSIX (!) which is obviously
undesirable and would introduce the same issues as the ones we observe on
Windows.
SetThreadDescription always uses UTF-16 on Windows and there is no C locale
or ACP version.
There are cases where using the current C locale makes sense and this is
not it, even from the C standpoint.
As implementers of one of the most popular open-source libraries that
includes this functionality and quoted in the paper (Folly), we won’t be
able to use the standard facility as proposed. Moreover, we’ll have to
implement a lint to warn against its use because of obvious encoding
issues, similarly to what we do for std::regex and other problematic
standard APIs. So the paper will not only fail to achieve its goals but
will even create more work to avoid the facility. Therefore we would prefer
not to have it at all than to have it standardized in such a flawed form.
There is another option that we haven't really discussed but which could
work, namely follow the std::format / std::print model (see e.g.
https://eel.is/c++draft/print.fun#2) and handle the Unicode case specially
which is what matters in the long term. Something along the lines of:
If the ordinary literal encoding ([lex.charset]) is UTF-8, the name hint is
transcoded to the encoding used by the underlying system API for setting
the thread name...
Hopefully this additional information based on real experiments as well as
implementation and usage experience with existing facilities will increase
consensus in favor of using either the literal encoding or the std::format
/ std::print model which both correctly handle all of the above cases while
still being compatible with locales in places where it matters.
Cheers,
Victor
On Wed, Oct 9, 2024 at 11:50 AM Tom Honermann <tom_at_[hidden]> wrote:
> On 10/9/24 9:41 AM, Victor Zverovich wrote:
>
> Hi Tom,
>
> Can we finish the review of P2019 Thread Attributes? The end of the last
> meeting was a bit rushed because we ran out of time and I don't think we
> even went through all the poll candidates.
>
> I don't mind continuing discussion on it if we have time left over today,
> but I'll be surprised if that is the case.
>
> I don't have other poll candidates for P2019 at the moment, but I agree
> that there is more to discuss. I don't think we resolved questions of
> behavior on POSIX vs Windows platforms and I believe you raised some
> possible concerns with the use of string_view that weren't discussed. If
> there are other items, please let me know. I've tentatively added further
> discussion to my list of topics for the 10/23 meeting.
>
> Tom.
>
>
> - Victor
>
> On Tue, Oct 8, 2024 at 2:28 PM Tom Honermann via SG16 <
> sg16_at_[hidden]> wrote:
>
>> SG16 will hold a meeting *tomorrow*, Wednesday, October 9th, at 19:30
>> UTC (timezone conversion
>> <https://www.timeanddate.com/worldclock/converter.html?iso=20241009T193000&p1=1440&p2=tz_pdt&p3=tz_mdt&p4=tz_cdt&p5=tz_edt&p6=tz_cest>
>> ).
>>
>> The agenda follows.
>>
>> - P3094R3: std::basic_fixed_string <https://wg21.link/p3094r3>
>> - P3045R1: Quantities and units library <https://wg21.link/p3045r1>
>> - P3258R0: Formatting of charN_t <https://wg21.link/p3258r0>
>>
>> SG16 has not previously reviewed P3094, but did discuss a fixed_string
>> type in the context of a predecessor paper, P2980R0 (A motivation,
>> scope, and plan for a physical quantities and units library)
>> <https://wg21.link/p2980r0> during its 2023-11-29 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README-2023.md#november-29th-2023>.
>> Since we're fairly familiar with the subject matter, so I'll ask Mateusz to
>> provide a brief overview and we'll move on to discussion of any concerns.
>> SG16 has not previously polled this paper or its predecessor; the LEWG
>> chair will be looking for SG16 to bless this paper even if we don't see
>> SG16 specific concerns to ensure this paper is ready for progress in
>> Wrocław.
>>
>> SG16 reviewed previous revisions of P3045 during its 2023-11-29 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README-2023.md#november-29th-2023>
>> and 2024-01-24 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README.md#january-24th-2024>.
>> Previous discussion concerned which encodings to support and representation
>> for symbols, particularly those not represented in the basic character
>> sets. Mateusz can provide an overview of the changes and any relevant
>> design changes that have been made. The LEWG chair will also be looking for
>> SG16 to determine if there are any lingering SG16 concerns that would
>> prevent this paper progressing at Wrocław.
>>
>> P3258R0 comes to us courtesy of Corentin and seeks to achieve what most
>> people expect to be trivial but which we have always known to be
>> impossible; provide formatting and I/O support for text in char*N*_t,
>> sort of, as limited by the characters representable in the ordinary and
>> wide literal encodings. Corentin to provide an overview and frown while the
>> rest of us quibble about transcoding details and locale encodings and,
>> probably, reluctantly, conclude that the behavior Corentin has proposed is
>> how things should be.
>>
>> Tom.
>> --
>> SG16 mailing list
>> SG16_at_[hidden]
>> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>>
>
I wanted to follow up on our recent telecon, as I realized that I may not
have fully conveyed important issues regarding the proposed thread name
facility. Specifically, its reliance on the C locale being fundamentally
incompatible with much of the standard C++ library and even the underlying
system APIs. To illustrate these concerns, I conducted a series of
experiments, summarized below:
1. Using C locale is incompatible with std::format, std::print and all
formatters where literal encoding is assumed throughout. Even the most
trivial use case similar to the one discussed last time doesn't work:
constexpr int num_threads = 2;
std::thread t[num_threads];
for (int i = 0; i < num_threads; ++i) {
t[i] = std::thread([] {
do_work();
});
set_thread_name_c_locale(t[i].native_handle(), std::format("нітка{}",
i).c_str());
}
where set_thread_name_c_locale is defined as follows:
void set_thread_name_c_locale(HANDLE h, const char* name) {
wchar_t buf[256];
mbstowcs(buf, name, 256);
SetThreadDescription(h, buf);
}
This gives mojibake on Windows with Belarusian localization. Here's an
output with literal encoding UTF-8 (although mojibake happens in non-UTF-8
case as well):
[image: image.png]
2. The proposed facility is inconsistent with std::to_string, which does
not use any locales:
set_thread_name_c_locale(t[i].native_handle(), ("нітка" +
std::to_string(i)).c_str());
Integral overloads never used locales and floating-point overloads won't
use locales as of C++26 and were broken previously anyway.
3. The facility is incompatible with iostreams, as they use the C++ locale
imbued in the stream for non-text components:
std::ostringstream os;
os << "нітка" << i;
set_thread_name_c_locale(t[i].native_handle(), os.str().c_str());
4. It is even incompatible with sprintf in common cases:
char name[16];
sprintf(name, "нітка%d", i);
set_thread_name_c_locale(t[i].native_handle(), name);
Note that sprintf doesn't use the C locale here. It was pointed out to me
by one of the C standard library maintainers when I was writing the
std::to_string paper and allowed us to completely eliminate the use of
locales in this API which was a major improvement.
All of those examples give incorrect thread name output shown earlier,
contrary to some information circulated during the previous discussion.
It would be very unfortunate to standardize a new facility that treats
non-English speaking C++ users as “second-class citizens" giving unusable
output / mojibake even in the most basic cases.
Neither pthread_setname_np nor pthread_getname_np assume the C locale
encoding. For example, quoting
https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html:
The thread name is a string of length 31 bytes or less, UTF-8 encoded.
This means that the POSIX implementation in P2019R7 is actually incorrect
and doesn’t match the wording. Making it match the wording may require
transcoding from the locale encoding on POSIX (!) which is obviously
undesirable and would introduce the same issues as the ones we observe on
Windows.
SetThreadDescription always uses UTF-16 on Windows and there is no C locale
or ACP version.
There are cases where using the current C locale makes sense and this is
not it, even from the C standpoint.
As implementers of one of the most popular open-source libraries that
includes this functionality and quoted in the paper (Folly), we won’t be
able to use the standard facility as proposed. Moreover, we’ll have to
implement a lint to warn against its use because of obvious encoding
issues, similarly to what we do for std::regex and other problematic
standard APIs. So the paper will not only fail to achieve its goals but
will even create more work to avoid the facility. Therefore we would prefer
not to have it at all than to have it standardized in such a flawed form.
There is another option that we haven't really discussed but which could
work, namely follow the std::format / std::print model (see e.g.
https://eel.is/c++draft/print.fun#2) and handle the Unicode case specially
which is what matters in the long term. Something along the lines of:
If the ordinary literal encoding ([lex.charset]) is UTF-8, the name hint is
transcoded to the encoding used by the underlying system API for setting
the thread name...
Hopefully this additional information based on real experiments as well as
implementation and usage experience with existing facilities will increase
consensus in favor of using either the literal encoding or the std::format
/ std::print model which both correctly handle all of the above cases while
still being compatible with locales in places where it matters.
Cheers,
Victor
On Wed, Oct 9, 2024 at 11:50 AM Tom Honermann <tom_at_[hidden]> wrote:
> On 10/9/24 9:41 AM, Victor Zverovich wrote:
>
> Hi Tom,
>
> Can we finish the review of P2019 Thread Attributes? The end of the last
> meeting was a bit rushed because we ran out of time and I don't think we
> even went through all the poll candidates.
>
> I don't mind continuing discussion on it if we have time left over today,
> but I'll be surprised if that is the case.
>
> I don't have other poll candidates for P2019 at the moment, but I agree
> that there is more to discuss. I don't think we resolved questions of
> behavior on POSIX vs Windows platforms and I believe you raised some
> possible concerns with the use of string_view that weren't discussed. If
> there are other items, please let me know. I've tentatively added further
> discussion to my list of topics for the 10/23 meeting.
>
> Tom.
>
>
> - Victor
>
> On Tue, Oct 8, 2024 at 2:28 PM Tom Honermann via SG16 <
> sg16_at_[hidden]> wrote:
>
>> SG16 will hold a meeting *tomorrow*, Wednesday, October 9th, at 19:30
>> UTC (timezone conversion
>> <https://www.timeanddate.com/worldclock/converter.html?iso=20241009T193000&p1=1440&p2=tz_pdt&p3=tz_mdt&p4=tz_cdt&p5=tz_edt&p6=tz_cest>
>> ).
>>
>> The agenda follows.
>>
>> - P3094R3: std::basic_fixed_string <https://wg21.link/p3094r3>
>> - P3045R1: Quantities and units library <https://wg21.link/p3045r1>
>> - P3258R0: Formatting of charN_t <https://wg21.link/p3258r0>
>>
>> SG16 has not previously reviewed P3094, but did discuss a fixed_string
>> type in the context of a predecessor paper, P2980R0 (A motivation,
>> scope, and plan for a physical quantities and units library)
>> <https://wg21.link/p2980r0> during its 2023-11-29 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README-2023.md#november-29th-2023>.
>> Since we're fairly familiar with the subject matter, so I'll ask Mateusz to
>> provide a brief overview and we'll move on to discussion of any concerns.
>> SG16 has not previously polled this paper or its predecessor; the LEWG
>> chair will be looking for SG16 to bless this paper even if we don't see
>> SG16 specific concerns to ensure this paper is ready for progress in
>> Wrocław.
>>
>> SG16 reviewed previous revisions of P3045 during its 2023-11-29 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README-2023.md#november-29th-2023>
>> and 2024-01-24 meeting
>> <https://github.com/sg16-unicode/sg16-meetings/blob/master/README.md#january-24th-2024>.
>> Previous discussion concerned which encodings to support and representation
>> for symbols, particularly those not represented in the basic character
>> sets. Mateusz can provide an overview of the changes and any relevant
>> design changes that have been made. The LEWG chair will also be looking for
>> SG16 to determine if there are any lingering SG16 concerns that would
>> prevent this paper progressing at Wrocław.
>>
>> P3258R0 comes to us courtesy of Corentin and seeks to achieve what most
>> people expect to be trivial but which we have always known to be
>> impossible; provide formatting and I/O support for text in char*N*_t,
>> sort of, as limited by the characters representable in the ordinary and
>> wide literal encodings. Corentin to provide an overview and frown while the
>> rest of us quibble about transcoding details and locale encodings and,
>> probably, reluctantly, conclude that the behavior Corentin has proposed is
>> how things should be.
>>
>> Tom.
>> --
>> SG16 mailing list
>> SG16_at_[hidden]
>> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>>
>
Received on 2024-10-23 18:05:25