Date: Tue, 13 Sep 2022 20:19:29 -0400
What implementation headaches would it cause to bump our Unicode reference?
TR31 identifier characters and named escapes might be impacted? Neither of
which is hard, but are still some work.
---------- Forwarded message ---------
From: announcements via announcements <announcements_at_[hidden]>
Date: Tue, Sep 13, 2022, 17:40
Subject: Announcing The Unicode® Standard, Version 15.0
To: <announcements_at_[hidden]>
Cc: announcements <announcements_at_[hidden]>
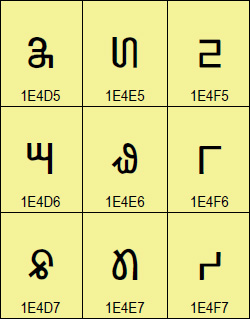
[image: [Nag Mundari image]]Version 15.0 of the Unicode Standard is now
available, including the core specification, annexes, and data files. This
version adds 4,489 characters, bringing the total to 149,186 characters.
These additions include two new scripts, for a total of 161 scripts, along
with 20 new emoji characters, and 4,193 CJK (Chinese, Japanese, and Korean)
ideographs. The new scripts and characters in Version 15.0 add support for
modern language groups including:
- Nag Mundari
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1E4D0.pdf>, a
modern script used to write Mundari, a language spoken in India
- A Kannada character used to write Konkani, Awadhi, and Havyaka Kannada
in India
- Kaktovik
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1D2C0.pdf>
numerals, devised by speakers of Iñupiaq in Kaktovik, Alaska for the
counting systems of the Inuit and Yupik languages
Among the popular symbol additions are 20 new emoji, including hair pick,
maracas, jellyfish, khanda, and pink heart. For the full list of new emoji
characters, see emoji additions for Unicode 15.0
<https://unicode.org/emoji/charts-15.0/emoji-released.html>, and Emoji
Counts <https://www.unicode.org/emoji/charts-15.0/emoji-counts.html>. For a
detailed description of support for emoji characters by the Unicode
Standard, see UTS #51, Unicode Emoji
<https://www.unicode.org/reports/tr51/tr51-23.html>.
[image: [Image credit Noto Emoji]]
<https://www.unicode.org/announcements/u15-emoji-annc-large.png>
Other symbol and notational additions include:
- The nine pointed white star, used by members of the Bahá’í faith
- Eight symbols for celestial bodies
<http://blog.unicode.org/2022/05/out-of-this-world-new-astronomy-symbols.html>,
used by astronomers and astrologers
- Twenty-nine additional Egyptian hieroglyph format controls
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-13430.pdf>, which
will enable Egyptologists to better represent texts
Support for other languages and scholarly work includes:
- Kawi <https://www.unicode.org/charts/PDF/Unicode-15.0/U150-11F00.pdf>,
a historical script found in Southeast Asia, used to write Old Javanese and
other languages
- Three additional characters for the Arabic script to support Quranic
marks used in Turkey
- Three Khojki characters found in handwritten and printed documents
- Ten Devanagari characters used to represent auspicious signs found in
inscriptions and manuscripts
- Six Latin letters used in Malayalam transliteration
- Sixty-three Cyrillic modifier letters used in phonetic transcription
Important chart font updates include:
- A set of updated glyphs for Egyptian
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-13000.pdf>
hieroglyphs, in addition to standardized variation sequences to support
rotated glyphs found in texts
- Improved glyphs for Unified Canadian Aboriginal Syllabics
<https://blog.unicode.org/2022/06/working-with-local-communities-to.html>,
which provide better support for Carrier and other languages
- A new Wancho
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1E2C0.pdf> font,
with improved and simplified shapes
Updates to the CJK blocks add:
- 4,192 ideographs in the new CJK Unified Ideographs Extension H block
- One ideograph in the CJK Unified Ideographs Extension C block
Unicode properties and specifications determine the behavior of text on
computers and phones. The following six Unicode Standard Annexes and
Technical Standards have noteworthy updates for Version 15.0:
- UAX #9 <https://www.unicode.org/reports/tr9/tr9-46.html>, Unicode
Bidirectional Algorithm, amends the note in UAX9-C2 to emphasize the use of
higher-level protocols to mitigate potential source code spoofing attacks.
- UAX #31 <https://www.unicode.org/reports/tr31/tr31-37.html>, Unicode
Identifier and Pattern Syntax, provides more guidance on profiles for
default identifiers, clarifies the use of default ignorable code points in
identifiers, and discusses the relationship between Pattern_White_Space and
bidirectional ordering issues in programming languages.
- UAX #38 <https://www.unicode.org/reports/tr38/tr38-33.html>, Unicode
Han Database, adds the kAlternateTotalStrokes property. The kCihaiT
property’s category was changed to Dictionary Indices, the kKangXi property
was expanded, and Sections 3.0, 3.10, and 4.5 were added.
- UTS #39 <https://www.unicode.org/reports/tr39/tr39-26.html>, Unicode
Security Mechanisms, changes the zero width joiner (ZWJ) and zero width
non-joiner (ZWNJ) characters from Identifier_Status=Allowed to
Identifier_Status=Restricted; they are therefore no longer allowed by the
General Security Profile by default.
- UAX #45 <https://www.unicode.org/reports/tr45/tr45-27.html>, U-Source
Ideographs, has records for new ideographs in its data file, “ExtH” was
added as a new status, the status identifiers for the existing CJK Unified
Ideographs blocks were improved, and Section 2.5 was added.
- UTS #46 <https://www.unicode.org/reports/tr46/tr46-29.html>, Unicode
IDNA Compatibility Processing, clarified the edge case of the empty label
in ToASCII and added documentation regarding the new IDNA derived property
data files.
About the Unicode Standard The Unicode Standard provides the basis for
processing, storage and seamless data interchange of text data in any
language in all modern software and information technology protocols. It
provides a uniform, universal architecture and encoding for all languages
of the world, with over 140,000 characters currently encoded.
Unicode is required by modern standards such as XML, Java, C#, ECMAScript
(JavaScript), LDAP, CORBA 3.0, WML, etc., and is the official way to
implement ISO/IEC 10646. It is a fundamental component of all modern
software.
For additional information on the Unicode Standard, please visit
https://home.unicode.org/.
About the Unicode Consortium The Unicode Consortium is a non-profit
organization founded to develop, extend and promote use of the Unicode
Standard and related globalization standards.
The membership of the consortium represents a broad spectrum of
corporations and organizations, many in the computer and information
processing industry. Members include: Adobe, Amazon, Apple, Emojipedia,
Google, Government of Bangladesh, International Emerging Technology Company
(ETCO), Meta, Microsoft, Netflix, Salesforce, SAP, Tamil Virtual Academy,
The University of California (Berkeley), Yat Labs, plus well over a hundred
Associate, Liaison, and Individual members. For a complete member list go
to https://home.unicode.org/membership/members/.
For more information, please contact the Unicode Consortium
https://home.unicode.org/connect/contact-unicode/.
------------------------------
*Over 144,000 characters are available for adoption
<https://www.unicode.org/consortium/adopt-a-character.html> to help the
Unicode Consortium’s work on digitally disadvantaged languages*
[image: [badge]] <https://www.unicode.org/consortium/adopt-a-character.html>
https://blog.unicode.org/2022/09/announcing-unicode-standard-version-150.html
TR31 identifier characters and named escapes might be impacted? Neither of
which is hard, but are still some work.
---------- Forwarded message ---------
From: announcements via announcements <announcements_at_[hidden]>
Date: Tue, Sep 13, 2022, 17:40
Subject: Announcing The Unicode® Standard, Version 15.0
To: <announcements_at_[hidden]>
Cc: announcements <announcements_at_[hidden]>
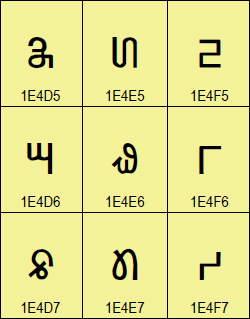
[image: [Nag Mundari image]]Version 15.0 of the Unicode Standard is now
available, including the core specification, annexes, and data files. This
version adds 4,489 characters, bringing the total to 149,186 characters.
These additions include two new scripts, for a total of 161 scripts, along
with 20 new emoji characters, and 4,193 CJK (Chinese, Japanese, and Korean)
ideographs. The new scripts and characters in Version 15.0 add support for
modern language groups including:
- Nag Mundari
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1E4D0.pdf>, a
modern script used to write Mundari, a language spoken in India
- A Kannada character used to write Konkani, Awadhi, and Havyaka Kannada
in India
- Kaktovik
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1D2C0.pdf>
numerals, devised by speakers of Iñupiaq in Kaktovik, Alaska for the
counting systems of the Inuit and Yupik languages
Among the popular symbol additions are 20 new emoji, including hair pick,
maracas, jellyfish, khanda, and pink heart. For the full list of new emoji
characters, see emoji additions for Unicode 15.0
<https://unicode.org/emoji/charts-15.0/emoji-released.html>, and Emoji
Counts <https://www.unicode.org/emoji/charts-15.0/emoji-counts.html>. For a
detailed description of support for emoji characters by the Unicode
Standard, see UTS #51, Unicode Emoji
<https://www.unicode.org/reports/tr51/tr51-23.html>.
[image: [Image credit Noto Emoji]]
<https://www.unicode.org/announcements/u15-emoji-annc-large.png>
Other symbol and notational additions include:
- The nine pointed white star, used by members of the Bahá’í faith
- Eight symbols for celestial bodies
<http://blog.unicode.org/2022/05/out-of-this-world-new-astronomy-symbols.html>,
used by astronomers and astrologers
- Twenty-nine additional Egyptian hieroglyph format controls
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-13430.pdf>, which
will enable Egyptologists to better represent texts
Support for other languages and scholarly work includes:
- Kawi <https://www.unicode.org/charts/PDF/Unicode-15.0/U150-11F00.pdf>,
a historical script found in Southeast Asia, used to write Old Javanese and
other languages
- Three additional characters for the Arabic script to support Quranic
marks used in Turkey
- Three Khojki characters found in handwritten and printed documents
- Ten Devanagari characters used to represent auspicious signs found in
inscriptions and manuscripts
- Six Latin letters used in Malayalam transliteration
- Sixty-three Cyrillic modifier letters used in phonetic transcription
Important chart font updates include:
- A set of updated glyphs for Egyptian
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-13000.pdf>
hieroglyphs, in addition to standardized variation sequences to support
rotated glyphs found in texts
- Improved glyphs for Unified Canadian Aboriginal Syllabics
<https://blog.unicode.org/2022/06/working-with-local-communities-to.html>,
which provide better support for Carrier and other languages
- A new Wancho
<https://www.unicode.org/charts/PDF/Unicode-15.0/U150-1E2C0.pdf> font,
with improved and simplified shapes
Updates to the CJK blocks add:
- 4,192 ideographs in the new CJK Unified Ideographs Extension H block
- One ideograph in the CJK Unified Ideographs Extension C block
Unicode properties and specifications determine the behavior of text on
computers and phones. The following six Unicode Standard Annexes and
Technical Standards have noteworthy updates for Version 15.0:
- UAX #9 <https://www.unicode.org/reports/tr9/tr9-46.html>, Unicode
Bidirectional Algorithm, amends the note in UAX9-C2 to emphasize the use of
higher-level protocols to mitigate potential source code spoofing attacks.
- UAX #31 <https://www.unicode.org/reports/tr31/tr31-37.html>, Unicode
Identifier and Pattern Syntax, provides more guidance on profiles for
default identifiers, clarifies the use of default ignorable code points in
identifiers, and discusses the relationship between Pattern_White_Space and
bidirectional ordering issues in programming languages.
- UAX #38 <https://www.unicode.org/reports/tr38/tr38-33.html>, Unicode
Han Database, adds the kAlternateTotalStrokes property. The kCihaiT
property’s category was changed to Dictionary Indices, the kKangXi property
was expanded, and Sections 3.0, 3.10, and 4.5 were added.
- UTS #39 <https://www.unicode.org/reports/tr39/tr39-26.html>, Unicode
Security Mechanisms, changes the zero width joiner (ZWJ) and zero width
non-joiner (ZWNJ) characters from Identifier_Status=Allowed to
Identifier_Status=Restricted; they are therefore no longer allowed by the
General Security Profile by default.
- UAX #45 <https://www.unicode.org/reports/tr45/tr45-27.html>, U-Source
Ideographs, has records for new ideographs in its data file, “ExtH” was
added as a new status, the status identifiers for the existing CJK Unified
Ideographs blocks were improved, and Section 2.5 was added.
- UTS #46 <https://www.unicode.org/reports/tr46/tr46-29.html>, Unicode
IDNA Compatibility Processing, clarified the edge case of the empty label
in ToASCII and added documentation regarding the new IDNA derived property
data files.
About the Unicode Standard The Unicode Standard provides the basis for
processing, storage and seamless data interchange of text data in any
language in all modern software and information technology protocols. It
provides a uniform, universal architecture and encoding for all languages
of the world, with over 140,000 characters currently encoded.
Unicode is required by modern standards such as XML, Java, C#, ECMAScript
(JavaScript), LDAP, CORBA 3.0, WML, etc., and is the official way to
implement ISO/IEC 10646. It is a fundamental component of all modern
software.
For additional information on the Unicode Standard, please visit
https://home.unicode.org/.
About the Unicode Consortium The Unicode Consortium is a non-profit
organization founded to develop, extend and promote use of the Unicode
Standard and related globalization standards.
The membership of the consortium represents a broad spectrum of
corporations and organizations, many in the computer and information
processing industry. Members include: Adobe, Amazon, Apple, Emojipedia,
Google, Government of Bangladesh, International Emerging Technology Company
(ETCO), Meta, Microsoft, Netflix, Salesforce, SAP, Tamil Virtual Academy,
The University of California (Berkeley), Yat Labs, plus well over a hundred
Associate, Liaison, and Individual members. For a complete member list go
to https://home.unicode.org/membership/members/.
For more information, please contact the Unicode Consortium
https://home.unicode.org/connect/contact-unicode/.
------------------------------
*Over 144,000 characters are available for adoption
<https://www.unicode.org/consortium/adopt-a-character.html> to help the
Unicode Consortium’s work on digitally disadvantaged languages*
[image: [badge]] <https://www.unicode.org/consortium/adopt-a-character.html>
https://blog.unicode.org/2022/09/announcing-unicode-standard-version-150.html


{kind=link}
Received on 2022-09-14 00:19:46