Date: Mon, 18 Nov 2024 14:58:24 +0100
Can we please take a decision?
As the author I fundamentally do not care about whether we pick the literal
or execution literal encoding, and I do not expect it will impact, in any
way shape or form
implementations (that will just assume the literal encoding is a subset of
the execution encoding)
However, we should not hold that paper on just that, we have time to
revisit that question later.
Thanks
On Wed, Oct 23, 2024 at 9:33 PM Victor Zverovich via SG16 <
sg16_at_[hidden]> wrote:
> > Could you please complete the picture here?
> > You said your example uses UTF-8 literal encoding.
>
> Yes, but a similar problem also exists for the legacy encoding case, only
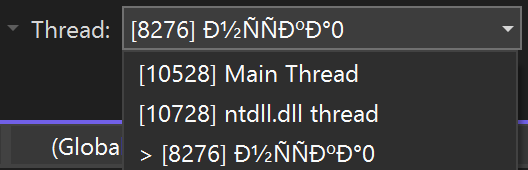
> the output is corrupted differently:
>
> [image: image.png]
>
> I presented the results for UTF-8 because this is what we care most about
> in the long term.
>
> > What's the C locale encoding for the execution character set
> > under the Windows Belarusian localization?
> > What's the expected input encoding for "mbstowcs" in that localization?
> > What's the generated output encoding for "mbstowcs" in that localization?
>
> The C locale is initialized to “C” by default which is not specific to
> Belarusian localization in any way. I haven’t checked which encoding
> mbstowcs is using in this case - can do it as a follow-up if there is
> interest, just reporting user-observable behavior which is obviously
> unsatisfactory.
>
> > (We already know that a literal encoding that is incompatible
> > with the locale's encoding is hard to program for.)
>
> Exactly and this is why the literal encoding is a good choice - it is
> detectable statically and the locale encoding, if set, should normally be
> compatible with it. Large parts of the design of std::format and
> std::print, approved by SG16 in C++20 and C++23, are based on this.
>
> > Note that pthread_setname_np is not in POSIX. What you quoted is the way
> > this function operates on Solaris.
>
> Sure, this particular API is not part of the POSIX standard but an
> implementation of pthreads. Even on Linux nothing says that the string is
> in the C locale encoding and looking at the implementation it is basically
> passed via a syscall “as is”. The main point is that according to the
> current wording the standard library has to do potentially lossy
> transcoding on some platforms, including one or more POSIX platforms, for
> no good reason.
>
> > What is "ACP version"?
>
> Active Code Page (ACP): most Windows APIs have Unicode (<FunctionName>W)
> and non-Unicode (<FunctionName>A) versions with the latter using ACP which
> is unrelated to the C locale encoding.
>
> - Victor
>
> On Wed, Oct 23, 2024 at 11:43 AM Jens Maurer <jens.maurer_at_[hidden]> wrote:
>
>>
>>
>> On 23/10/2024 20.05, Victor Zverovich via SG16 wrote:
>> > This gives mojibake on Windows with Belarusian localization.
>>
>> Could you please complete the picture here?
>> You said your example uses UTF-8 literal encoding.
>> What's the C locale encoding for the execution character set
>> under the Windows Belarusian localization?
>> What's the expected input encoding for "mbstowcs" in that localization?
>> What's the generated output encoding for "mbstowcs" in that localization?
>>
>> (We already know that a literal encoding that is incompatible
>> with the locale's encoding is hard to program for.)
>>
>> > Neither pthread_setname_np nor pthread_getname_np assume the C locale
>> encoding. For example, quoting
>> https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html
>> <
>> https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html
>> >:
>> >
>> > The thread name is a string of length 31 bytes or less, UTF-8
>> encoded.
>>
>> Note that pthread_setname_np is not in POSIX. What you quoted is the way
>> this function operates on Solaris.
>>
>> In contrast, my Linux man page says:
>>
>> The thread name is a meaningful C language string,
>> whose length is restricted to 16 characters, including the
>> terminating null byte ('\0').
>>
>> (No, I don't know what "meaningful" means.)
>>
>> > This means that the POSIX implementation in P2019R7 is actually
>> incorrect and doesn’t match the wording.
>>
>> The paper says "on most POSIX implementation". Apparently, Solaris is
>> different here.
>> Are there any non-UTF environments on Solaris these days?
>> Would Solaris transcode from UTF-8 to the encoding of that other
>> environment?
>> I doubt it. Thread names are just few bytes in a special memory area
>> where
>> the usual tools can find them; I can't imagine any Unix doing any sort of
>> encoding recognition/translation when setting a name.
>>
>> Do you have a more complete survey of Unix-like operating systems?
>>
>> > SetThreadDescription always uses UTF-16 on Windows and there is no C
>> locale or ACP version.
>>
>> What is "ACP version"?
>>
>> We already know we have to transcode for Windows (because wchar_t),
>> but all the standard tools such as mbstowcs use the encoding specified by
>> the C locale (input and output), so they're unsuitable to reliably output
>> UTF-16.
>>
>> Maybe we want our set_thread_name to simply take char8_t (in UTF-8
>> encoding)
>> and be done with it. And no, I'm not worried about copying / transcoding
>> 16-32 bytes even on Unix.
>>
>> Jens
>>
>> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>
As the author I fundamentally do not care about whether we pick the literal
or execution literal encoding, and I do not expect it will impact, in any
way shape or form
implementations (that will just assume the literal encoding is a subset of
the execution encoding)
However, we should not hold that paper on just that, we have time to
revisit that question later.
Thanks
On Wed, Oct 23, 2024 at 9:33 PM Victor Zverovich via SG16 <
sg16_at_[hidden]> wrote:
> > Could you please complete the picture here?
> > You said your example uses UTF-8 literal encoding.
>
> Yes, but a similar problem also exists for the legacy encoding case, only
> the output is corrupted differently:
>
> [image: image.png]
>
> I presented the results for UTF-8 because this is what we care most about
> in the long term.
>
> > What's the C locale encoding for the execution character set
> > under the Windows Belarusian localization?
> > What's the expected input encoding for "mbstowcs" in that localization?
> > What's the generated output encoding for "mbstowcs" in that localization?
>
> The C locale is initialized to “C” by default which is not specific to
> Belarusian localization in any way. I haven’t checked which encoding
> mbstowcs is using in this case - can do it as a follow-up if there is
> interest, just reporting user-observable behavior which is obviously
> unsatisfactory.
>
> > (We already know that a literal encoding that is incompatible
> > with the locale's encoding is hard to program for.)
>
> Exactly and this is why the literal encoding is a good choice - it is
> detectable statically and the locale encoding, if set, should normally be
> compatible with it. Large parts of the design of std::format and
> std::print, approved by SG16 in C++20 and C++23, are based on this.
>
> > Note that pthread_setname_np is not in POSIX. What you quoted is the way
> > this function operates on Solaris.
>
> Sure, this particular API is not part of the POSIX standard but an
> implementation of pthreads. Even on Linux nothing says that the string is
> in the C locale encoding and looking at the implementation it is basically
> passed via a syscall “as is”. The main point is that according to the
> current wording the standard library has to do potentially lossy
> transcoding on some platforms, including one or more POSIX platforms, for
> no good reason.
>
> > What is "ACP version"?
>
> Active Code Page (ACP): most Windows APIs have Unicode (<FunctionName>W)
> and non-Unicode (<FunctionName>A) versions with the latter using ACP which
> is unrelated to the C locale encoding.
>
> - Victor
>
> On Wed, Oct 23, 2024 at 11:43 AM Jens Maurer <jens.maurer_at_[hidden]> wrote:
>
>>
>>
>> On 23/10/2024 20.05, Victor Zverovich via SG16 wrote:
>> > This gives mojibake on Windows with Belarusian localization.
>>
>> Could you please complete the picture here?
>> You said your example uses UTF-8 literal encoding.
>> What's the C locale encoding for the execution character set
>> under the Windows Belarusian localization?
>> What's the expected input encoding for "mbstowcs" in that localization?
>> What's the generated output encoding for "mbstowcs" in that localization?
>>
>> (We already know that a literal encoding that is incompatible
>> with the locale's encoding is hard to program for.)
>>
>> > Neither pthread_setname_np nor pthread_getname_np assume the C locale
>> encoding. For example, quoting
>> https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html
>> <
>> https://docs.oracle.com/cd/E88353_01/html/E37843/pthread-setname-np-3c.html
>> >:
>> >
>> > The thread name is a string of length 31 bytes or less, UTF-8
>> encoded.
>>
>> Note that pthread_setname_np is not in POSIX. What you quoted is the way
>> this function operates on Solaris.
>>
>> In contrast, my Linux man page says:
>>
>> The thread name is a meaningful C language string,
>> whose length is restricted to 16 characters, including the
>> terminating null byte ('\0').
>>
>> (No, I don't know what "meaningful" means.)
>>
>> > This means that the POSIX implementation in P2019R7 is actually
>> incorrect and doesn’t match the wording.
>>
>> The paper says "on most POSIX implementation". Apparently, Solaris is
>> different here.
>> Are there any non-UTF environments on Solaris these days?
>> Would Solaris transcode from UTF-8 to the encoding of that other
>> environment?
>> I doubt it. Thread names are just few bytes in a special memory area
>> where
>> the usual tools can find them; I can't imagine any Unix doing any sort of
>> encoding recognition/translation when setting a name.
>>
>> Do you have a more complete survey of Unix-like operating systems?
>>
>> > SetThreadDescription always uses UTF-16 on Windows and there is no C
>> locale or ACP version.
>>
>> What is "ACP version"?
>>
>> We already know we have to transcode for Windows (because wchar_t),
>> but all the standard tools such as mbstowcs use the encoding specified by
>> the C locale (input and output), so they're unsuitable to reliably output
>> UTF-16.
>>
>> Maybe we want our set_thread_name to simply take char8_t (in UTF-8
>> encoding)
>> and be done with it. And no, I'm not worried about copying / transcoding
>> 16-32 bytes even on Unix.
>>
>> Jens
>>
>> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>
Received on 2024-11-18 13:58:44