Date: Wed, 14 Dec 2022 14:04:10 -0500
On 12/14/22 1:57 PM, Victor Zverovich wrote:
> Tom, thanks for the additional analysis, glad to see the results agree
> with the paper. I believe you meant "For the characters that the paper
> changes from width 2 to width 1" in the second top-level bullet point.
Thank you, yes; copy paste bug.
>
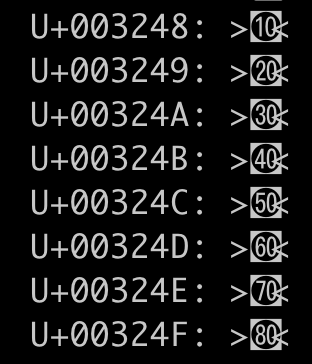
> As another data point, U+003248 .. U+00324F (CIRCLED NUMBER TEN ON
> BLACK SQUARE .. CIRCLED NUMBER EIGHTY ON BLACK SQUARE) are all
> rendered incorrectly both on iTerm and macOS Terminal. They have
> essentially the same problem as those unassigned characters we
> discussed last time which are rendered as width 2 but overlap with the
> following characters as if they have width 1.
That is probably better behavior than letting the font determine the
width. At least the positional behavior remains consistent regardless of
font choice.
Tom.
>
> - Victor
>
> image.png
>
> On Wed, Dec 14, 2022 at 10:30 AM Tom Honermann via SG16
> <sg16_at_[hidden]> wrote:
>
> On 11/30/22 5:26 PM, Corentin via SG16 wrote:
>> Hello folks.
>> Here is a list of all the codepoint that change
>> https://gist.githubusercontent.com/cor3ntin/b7f4f52893b0b54890e970f7bbec6118/raw/720a910585d78c9ceb4e0458dcef87af2a436121/width.md
>
> Just a note: the gist has 8570 characters and that count matches
> the ranges specified in the D2675R1
> <https://isocpp.org/files/papers/D2675R1.pdf> annex.
>
>>
>> Simply cat that file in the terminal.
>> The screenshot below is a render on ITerm2
>> You will notice the tofu for reserved codepoints is considered narrow
>> but doesn't quite fit so it overlaps with the next cell, same for
>> the number in square.
>>
>>
>> Screenshot 2022-11-30 at 23.19.47.png
>
> As discussed previously, a single screen shot that only shows a
> small subset of the relevant characters is not sufficient to
> demonstrate that the conclusions of the paper are consistent with
> existing behavior. I continue to have reservations about the
> screen shots in the paper for this reason; I don't see how they
> provide useful information at all. I think they are actively
> misleading since they do not appear to show behavior that is
> consistent with the intent of the paper.
>
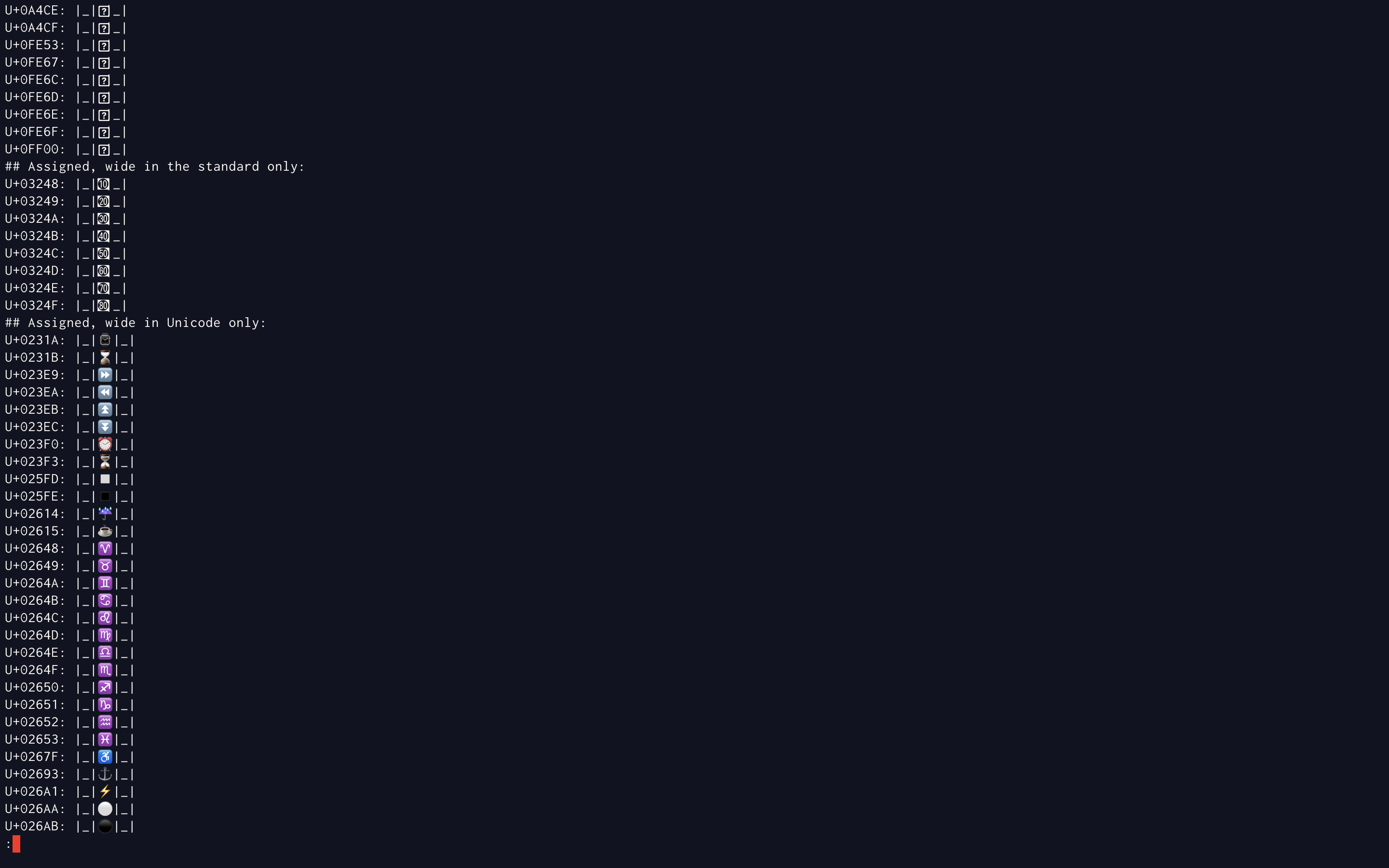
> I spent some time analyzing the behavior of all 8570 characters in
> the terminal I use (Konsole 12.12.3 with the Hack 10pt font). Here
> is what I found:
>
> * For the characters that the paper changes from width 1 to
> width 2 (based on the listings in the annex), the following
> are displayed with a width other than 2:
> o Width 0:
> + U+016FE4 (KHITAN SMALL SCRIPT FILLER)
> o Width 1: (These were all displayed as tofu; some are
> probably unassigned characters, others are probably
> unknown by the font)
> + U+01AFF0 .. U+01AFFE
> + U+01B11F .. U+01B132
> + U+01B155
> + U+01F6DC .. U+01F6DF
> + U+01F7F0
> + U+01FA75 .. U+01FA77
> + U+01FA7B .. U+01FA7C
> + U+01FA87 .. U+01FA88
> + U+01FAA9 .. U+01FAAF
> + U+01FAB7 .. U+01FABF
> + U+01FAC3 .. U+01FACF
> + U+01FAD7 .. U+01FAF8
> * For the characters that the paper changes from width 1 to
> width 2 (based on the listings in the annex), the following
> are displayed with a width other than 1:
> o Width 2:
> + U+003248 .. U+00324F (CIRCLED NUMBER TEN ON BLACK
> SQUARE .. CIRCLED NUMBER EIGHTY ON BLACK SQUARE)
>
> These results strongly match the intent of the paper and that the
> open question regarding the last group of characters should be
> answered such that they do not change width.
>
> This is the kind of analysis I would like to see performed for
> other terminals so that we can qualitatively compare behavior
> between them. I attached C++ source code I used to display the
> characters.
>
> Tom.
>
>>
>>
>> FYI Iterm2 also uses Unicode UAX 44
>> https://github.com/gnachman/iTerm2/blob/master/sources/NSCharacterSet+iTerm.m#L464
>>
> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>
> Tom, thanks for the additional analysis, glad to see the results agree
> with the paper. I believe you meant "For the characters that the paper
> changes from width 2 to width 1" in the second top-level bullet point.
Thank you, yes; copy paste bug.
>
> As another data point, U+003248 .. U+00324F (CIRCLED NUMBER TEN ON
> BLACK SQUARE .. CIRCLED NUMBER EIGHTY ON BLACK SQUARE) are all
> rendered incorrectly both on iTerm and macOS Terminal. They have
> essentially the same problem as those unassigned characters we
> discussed last time which are rendered as width 2 but overlap with the
> following characters as if they have width 1.
That is probably better behavior than letting the font determine the
width. At least the positional behavior remains consistent regardless of
font choice.
Tom.
>
> - Victor
>
> image.png
>
> On Wed, Dec 14, 2022 at 10:30 AM Tom Honermann via SG16
> <sg16_at_[hidden]> wrote:
>
> On 11/30/22 5:26 PM, Corentin via SG16 wrote:
>> Hello folks.
>> Here is a list of all the codepoint that change
>> https://gist.githubusercontent.com/cor3ntin/b7f4f52893b0b54890e970f7bbec6118/raw/720a910585d78c9ceb4e0458dcef87af2a436121/width.md
>
> Just a note: the gist has 8570 characters and that count matches
> the ranges specified in the D2675R1
> <https://isocpp.org/files/papers/D2675R1.pdf> annex.
>
>>
>> Simply cat that file in the terminal.
>> The screenshot below is a render on ITerm2
>> You will notice the tofu for reserved codepoints is considered narrow
>> but doesn't quite fit so it overlaps with the next cell, same for
>> the number in square.
>>
>>
>> Screenshot 2022-11-30 at 23.19.47.png
>
> As discussed previously, a single screen shot that only shows a
> small subset of the relevant characters is not sufficient to
> demonstrate that the conclusions of the paper are consistent with
> existing behavior. I continue to have reservations about the
> screen shots in the paper for this reason; I don't see how they
> provide useful information at all. I think they are actively
> misleading since they do not appear to show behavior that is
> consistent with the intent of the paper.
>
> I spent some time analyzing the behavior of all 8570 characters in
> the terminal I use (Konsole 12.12.3 with the Hack 10pt font). Here
> is what I found:
>
> * For the characters that the paper changes from width 1 to
> width 2 (based on the listings in the annex), the following
> are displayed with a width other than 2:
> o Width 0:
> + U+016FE4 (KHITAN SMALL SCRIPT FILLER)
> o Width 1: (These were all displayed as tofu; some are
> probably unassigned characters, others are probably
> unknown by the font)
> + U+01AFF0 .. U+01AFFE
> + U+01B11F .. U+01B132
> + U+01B155
> + U+01F6DC .. U+01F6DF
> + U+01F7F0
> + U+01FA75 .. U+01FA77
> + U+01FA7B .. U+01FA7C
> + U+01FA87 .. U+01FA88
> + U+01FAA9 .. U+01FAAF
> + U+01FAB7 .. U+01FABF
> + U+01FAC3 .. U+01FACF
> + U+01FAD7 .. U+01FAF8
> * For the characters that the paper changes from width 1 to
> width 2 (based on the listings in the annex), the following
> are displayed with a width other than 1:
> o Width 2:
> + U+003248 .. U+00324F (CIRCLED NUMBER TEN ON BLACK
> SQUARE .. CIRCLED NUMBER EIGHTY ON BLACK SQUARE)
>
> These results strongly match the intent of the paper and that the
> open question regarding the last group of characters should be
> answered such that they do not change width.
>
> This is the kind of analysis I would like to see performed for
> other terminals so that we can qualitatively compare behavior
> between them. I attached C++ source code I used to display the
> characters.
>
> Tom.
>
>>
>>
>> FYI Iterm2 also uses Unicode UAX 44
>> https://github.com/gnachman/iTerm2/blob/master/sources/NSCharacterSet+iTerm.m#L464
>>
> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>
Received on 2022-12-14 19:04:12