Date: Wed, 9 Feb 2022 14:04:35 -0500
Begin forwarded message:
> From: announcements via announcements <announcements_at_[hidden]>
> Date: February 9, 2022 at 1:35:45 PM EST
> To: announcements_at_[hidden]
> Cc: announcements <announcements_at_[hidden]>
> Subject: Enhancements to Unicode Regular Expressions
> Reply-To: root_at_[hidden]
>
>
> A new revision of UTS #18, Unicode Regular Expressions is now available.
>
> Regular expressions are a key tool in software development. Back in 2000, few regular expression engines supported Unicode, even at a basic level. UTS #18 set out to raise the bar, describing how regular expression engines could be adapted to deal with Unicode correctly and completely. Since that time, major programming languages and libraries have adopted level 1 features (supporting all Unicode literals, basic character properties, subtraction, intersection, ...), and some also adopted some level 2 features (full character properties, grapheme clusters, ...).
>
> The main focus in this release is on handling the complement of properties of strings. The distinction is drawn between code point complement and full complement, followed by explicitly defining the complement operator [^...] to be code point complement, and providing the reasons for doing so in an annex. The important difference between [A--B] and [A&&[^B]] is outlined — setting out the reasons why the latter is insufficient to represent set difference.
>
> For the EBNF in general, and for character classes with strings in particular, examples were added and the text clarified. A new annex provides examples for how character classes can be parsed.
>
> Over 144,000 characters are available for adoption to help the Unicode Consortium’s work on digitally disadvantaged languages
>
>
>
> http://blog.unicode.org/2022/02/enhancements-to-unicode-regular.html
>
> From: announcements via announcements <announcements_at_[hidden]>
> Date: February 9, 2022 at 1:35:45 PM EST
> To: announcements_at_[hidden]
> Cc: announcements <announcements_at_[hidden]>
> Subject: Enhancements to Unicode Regular Expressions
> Reply-To: root_at_[hidden]
>
>
> A new revision of UTS #18, Unicode Regular Expressions is now available.
>
> Regular expressions are a key tool in software development. Back in 2000, few regular expression engines supported Unicode, even at a basic level. UTS #18 set out to raise the bar, describing how regular expression engines could be adapted to deal with Unicode correctly and completely. Since that time, major programming languages and libraries have adopted level 1 features (supporting all Unicode literals, basic character properties, subtraction, intersection, ...), and some also adopted some level 2 features (full character properties, grapheme clusters, ...).
>
> The main focus in this release is on handling the complement of properties of strings. The distinction is drawn between code point complement and full complement, followed by explicitly defining the complement operator [^...] to be code point complement, and providing the reasons for doing so in an annex. The important difference between [A--B] and [A&&[^B]] is outlined — setting out the reasons why the latter is insufficient to represent set difference.
>
> For the EBNF in general, and for character classes with strings in particular, examples were added and the text clarified. A new annex provides examples for how character classes can be parsed.
>
> Over 144,000 characters are available for adoption to help the Unicode Consortium’s work on digitally disadvantaged languages
>
>
>
> http://blog.unicode.org/2022/02/enhancements-to-unicode-regular.html
>
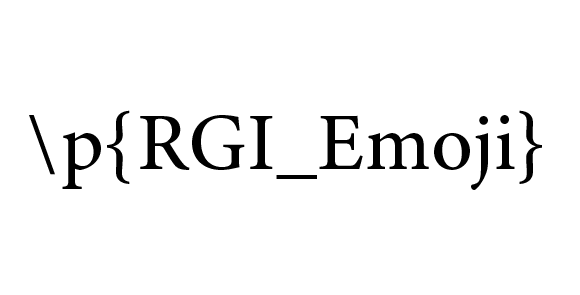

Received on 2022-02-09 19:04:37