Date: Tue, 27 Apr 2021 11:32:38 +0200
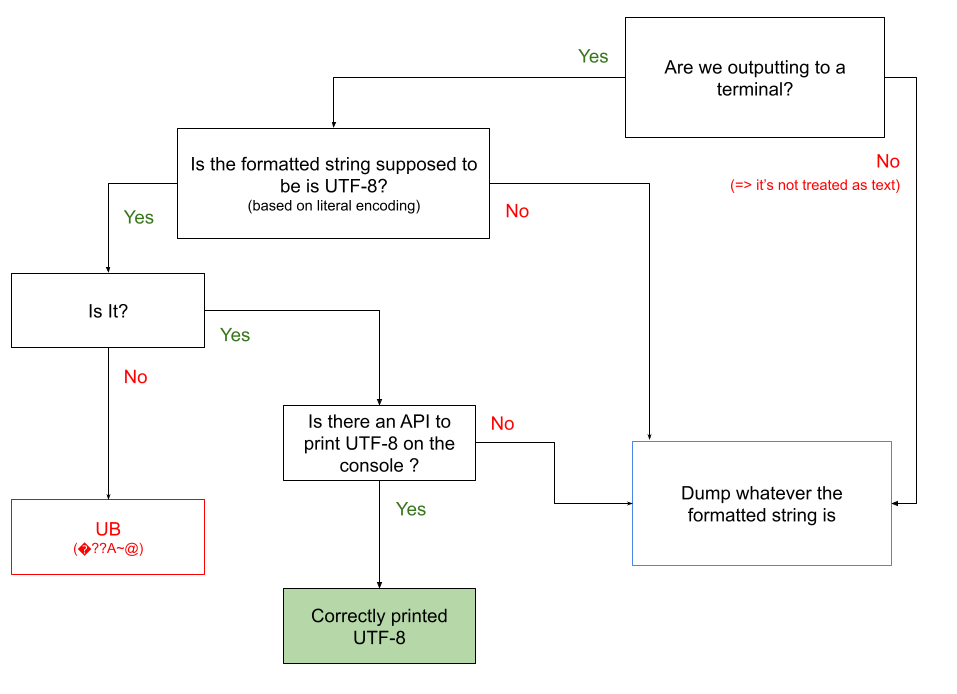
Maybe a drawing will be helpful for LEWG
[image: Untitled drawing (20).png]
On Tue, Apr 27, 2021 at 8:34 AM Corentin Jabot <corentinjabot_at_[hidden]>
wrote:
>
>
> On Tue, Apr 27, 2021 at 5:57 AM Tom Honermann <tom_at_[hidden]> wrote:
>
>> On 4/26/21 1:04 PM, Corentin Jabot via SG16 wrote:
>>
>>
>>
>> On Mon, Apr 26, 2021 at 6:19 PM Tom Honermann via SG16 <
>> sg16_at_[hidden]> wrote:
>>
>>> On 4/19/21 10:58 AM, Tom Honermann via SG16 wrote:
>>>
>>> SG16 will hold a telecon on Wednesday, April 28th at 19:30 UTC (timezone
>>> conversion
>>> <https://www.timeanddate.com/worldclock/converter.html?iso=20210428T193000&p1=1440&p2=tz_pdt&p3=tz_mdt&p4=tz_cdt&p5=tz_edt&p6=tz_cest>
>>> ).
>>>
>>> The agenda is:
>>>
>>> - P2093R5: Formatted output <https://wg21.link/p2093r5>
>>> - P2348R0: Whitespaces Wording Revamp
>>> <https://isocpp.org/files/papers/P2348R0.pdf>
>>>
>>> LEWG discussed P2093R5 at their 2021-04-06 telecon and decided to refer
>>> the paper back to SG16 for further discussion. LEWG meeting minutes are
>>> available here
>>> <https://wiki.edg.com/bin/view/Wg21telecons2021/P2093#Library-Evolution-2021-04-06>;
>>> please review them prior to the telecon. LEWG reviewed the list of prior
>>> SG16 deferred questions posted to them here
>>> <http://lists.isocpp.org/lib-ext/2021/03/18189.php>. Of those, they
>>> established consensus on an answer for #2 (they agreed not to block
>>> std::print() on a proposal for underlying terminal facilities), but
>>> referred the rest back to us. My interpretation of their actions is that
>>> LEWG would like a revision of the paper to address these concerns based on
>>> SG16 input (e.g., discuss design options and SG16 consensus or lack
>>> thereof). We'll therefore focus on these questions at this telecon.
>>>
>>> Hubert provided the following very interesting example usage.
>>>
>>> std::print("{:%r}\n",
>>> std::chrono::system_clock::now().time_since_epoch());
>>>
>>> At issue is the encoding used by locale sensitive chrono formatters.
>>> Search [time.format] <http://eel.is/c++draft/time.format> for "locale"
>>> to find example chrono format specifiers that are locale dependent. The
>>> example above contains the %r specifier and is locale sensitive because
>>> AM/PM designations may be localized. In a Chinese locale the desired
>>> translation of "PM" is "下午", but the locale will provide the translation in
>>> the locale encoding. As specified in P2093R5, if the execution (literal)
>>> encoding is UTF-8, than std::print() will expect the translation to be
>>> provided in UTF-8, but if the locale is not UTF-8-based (e.g., Big5;
>>> perhaps Shift-JIS for the Japanese 午後 translation), then the result is
>>> mojibake. This is a good example of how locale conflates translation and
>>> character encoding.
>>>
>>> Addressing the above will be our first order of business. Please
>>> reserve some time to independently think about this problem (ignore
>>> responses to this message for a few days if you need to). I am explicitly
>>> not listing possible approaches to address this concern in this message so
>>> as to avoid adding (further) bias in any specific direction. I suspect the
>>> answers to the previously deferred SG16 questions will be easier to answer
>>> once this concern is resolved.
>>>
>>> Now that we've all had some time to think about this issue, here are
>>> some possible directions we can pursue to resolve it. These are presented
>>> in no particular order.
>>>
>>> - Specialize std::locale facets
>>> <https://en.cppreference.com/w/cpp/locale/locale> and related I/O
>>> manipulators like std::put_time()
>>> <https://en.cppreference.com/w/cpp/io/manip/put_time> for char8_t.
>>> This would allow std::print() to, when the literal encoding is
>>> UTF-8, opt-in to use of the UTF-8/char8_t facets and I/O
>>> manipulators.
>>> - When the literal encoding is UTF-8, stipulate that running the
>>> program in a non-UTF-8 based locale is non-conforming. This would
>>> effectively require MSVC programmers to, when building code with the
>>> /utf-8 option, to also force selection of a UTF-8 code page via a
>>> manifest
>>> <https://docs.microsoft.com/en-us/windows/uwp/design/globalizing/use-utf8-code-page>
>>> and require use of Windows 10 build 1903 or later.
>>> - When the literal encoding is UTF-8, specify that non-UTF-8 based
>>> locale dependent translations be implicitly transcoded (such transcoding
>>> should never result in errors except perhaps for memory allocation
>>> failures).
>>> - Drop the special case handling for the literal encoding being
>>> UTF-8 and specify that, when bypassing a stream to write directly to the
>>> console, that the output be implicitly transcoded from the current locale
>>> dependent encoding (whatever it is) to the console encoding (UTF-8).
>>>
>>>
>> We have 2 things to explain to LEWG for print. And we do not need to
>> operate change to the design, just to explain things to them in a terms
>> they can understand (and they want to rely on our expertise which
>> implies consensus among ourselves)
>>
>> 1. It is always non-sense to interpret a string in encoding X when it is
>> in fact not.
>> 2. From there, if a string literal is in UTF-8, we HAVE to assume the
>> execution encoding is also utf-8. Why rely on the literal encoding and not
>> execution? it is resilient to call to setlocale and more efficient. Also,
>> format strings are likely to be literals.
>> 3. From there if that string is displayed on a
>> terminal/console/screen/tty, it is text. So it has to be rendered
>> correctly. On a specific system (windows) there is a way to enforce that.
>> Because windows has a separate mechanism for unicode display and console
>> handling that exists independently of the C++ execution encoding.
>> 4. "we have to assume" in 2. implies a precondition. That is true
>> REGARDLESS of utf-8 or not. in all cases the format string has to be
>> interpreted as text, which assumes it is valid in the execution encoding.
>> CF the Microsoft STL issue for braces in shift JS.
>> 5. This means that converting to UTF-16 on windows for the purpose of
>> console display is always valid (no ""transcosding"" error) within the
>> contract of the function, and as such does not have to be specified.
>> Preconditions violations are UB within the standard library and we should
>> keep doing that. In practice the implementation (which is here the
>> terminal, not the stl) will do character replacement the best it can, or
>> render something horrible.
>>
>> I agree with all of that, but I don't see how it relates to the
>> problematic example above. The issue with the example is that the "%r"
>> field specifier may cause non-UTF-8 content supplied by the locale to be
>> written.
>>
> I see two problems here.
> One is that this should not be locale dependent by default - has that been
> discussed? It seems to run amok of fmt design.
>
> The other is that, if print("xxx{}", foo) assumes that xxx is utf8, and
> the formated result is displayed onto a terminal, then the entire thing
> _has to_ be utf-8. note that this is because of
> a precondition on the act if displaying on the terminal which has nothing
> to do with formatting it's a 2 step process format -> print on terminal
> both of which have different preconditions (formating puts a requirement on
> the format string, to parse it, print additionally puts preconditions that
> the resulting thing will be utf8 such that individual arguments have to be
> to.
>
>
>>
>> The locale in there is a red herring. Changing the execution encoding is
>> always dicey - all strings that were correctly interpreted correctly
>> before the locale change are potentially no longer
>> correctly interpreted because their encoding no longer matches the new
>> execution encoding.
>> The existence of a setlocale function doesn't imply that calling it leads
>> to sensible results if the locale change also changes the encoding :)
>>
>> The example doesn't assume a locale change, at least not beyond an
>> initial std::setlocale(LC_ALL, "") during program startup.
>>
>>
>>
>> > Specialize std::locale facets
>> <https://en.cppreference.com/w/cpp/locale/locale> and related I/O
>> manipulators like std::put_time()
>> <https://en.cppreference.com/w/cpp/io/manip/put_time> for char8_t. This
>> would allow std::print() to, when the literal encoding is UTF-8, opt-in
>> to use of the UTF-8/char8_t facets and I/O manipulators.
>>
>> This is a different issue, one Peter and I have discussed. we should not
>> try to shove char into char8_t. Both char8_t and utf-8 char are valid use
>> cases. Also, the whole point of fmt::print is to avoid all of that :)
>>
>> I think this is strongly related, or we are misunderstanding each other.
>> I see the point of std::print() being to bypass the implicit (wrong)
>> console transcoding.
>>
> fmt::print just dumps the bytes in the general case, similarly to printf,
> that is then interpreted incorrectly by the windows console. I don't see
> where there might be transcoding
> in the program (I expect the console to do interesting things, but that's
> outside of C++).
>
> C++ thinks a string is Utf-8
> System (incorrectly) disagrees
> System has a method that allows it to agree
> Do we use that method?
>
> I strongly agree that char8_t and UTF-8 char are valid use cases.
>>
>>
>> > When the literal encoding is UTF-8, stipulate that running the program
>> in a non-UTF-8 based locale is non-conforming. This would effectively
>> require MSVC programmers to, when building code with the /utf-8 option,
>> to also force selection of a UTF-8 code page via a manifest
>> <https://docs.microsoft.com/en-us/windows/uwp/design/globalizing/use-utf8-code-page>
>> and require use of Windows 10 build 1903 or later.
>>
>> If you program contains literals that are not correctly interpreted by
>> the execution encoding, the behavior of your program cannot be correct
>> <insert scary U word>. So they should probably do that but it seems out of
>> scope.
>> The literalS encoding and the execution encoding should be consistent
>> (each string literal should be correctly interpreted).
>>
>> > When the literal encoding is UTF-8, specify that non-UTF-8 based locale
>> dependent translations be implicitly transcoded
>> Sorry, can you detail what you mean? I do not understand, sorry
>>
>> In the example above, the "%r" field specifier indicates that a locale
>> dependent 12-hour clock time be formatted. The AM/PM designator to be
>> formatted is locale dependent. If the locale is not UTF-8 based, then
>> mojibake is produced (if the literal encoding is UTF-8). This suggestion
>> addresses the problem by implicitly transcoding the locale dependent AM/PM
>> designator from the locale encoding to UTF-8 when formatting the output.
>>
>
> Think about cases in which that can happen
> There is a non-utf8 locale and a utf8 string literal mixed together.
>
>
>>
>> > Drop the special case handling for the literal encoding being UTF-8 and
>> specify that, when bypassing a stream to write directly to the console,
>> that the output be implicitly transcoded from the current locale dependent
>> encoding (whatever it is) to the console encoding (UTF-8).
>>
>> Dropping the special case seems more difficult in terms of wording.
>>
>> I think it is simpler actually; we would just have to say that the
>> implicit transcoding is from the locale encoding to the console encoding.
>>
>
> It's really hard to know what the console encoding is (it is a very
> microsoft specific thing), and the windows console basically have a wide
> (utf16) and narrow encoding (not sure it works exactly like that but it's a
> good enough model)
> Transcoding in the general case might be worse.
> A wording that encourages vendors to... encourage utf8 content to not be
> misinterpreted as something else might help but good luck wording that!
> Especially as it needs to handle file redirection, etc
>
>
>> If everything else fails, Microsoft could do the sensible thing as a
>> matter of QOL.
>>
>> Agreed.
>>
>> Tom.
>>
>>
>>
>>
>>> Please feel free to comment on these, or additional, approaches before
>>> our meeting on Wednesday.
>>>
>>> I think it would benefit LEWG if a revision of the paper presented each
>>> of these possibilities, the consequences, and the rationale (and hopefully
>>> SG16 consensus) for the proposed direction.
>>>
>>> Tom.
>>>
>>> I do not intend to time limit discussion of P2093R5 as I believe this is
>>> an important matter to resolve. If we are able to complete discussion of
>>> P2093R5, then we'll discuss P2348R0.
>>>
>>> Tom.
>>>
>>>
>>> --
>>> SG16 mailing list
>>> SG16_at_[hidden]
>>> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>>>
>>
>>
>>
[image: Untitled drawing (20).png]
On Tue, Apr 27, 2021 at 8:34 AM Corentin Jabot <corentinjabot_at_[hidden]>
wrote:
>
>
> On Tue, Apr 27, 2021 at 5:57 AM Tom Honermann <tom_at_[hidden]> wrote:
>
>> On 4/26/21 1:04 PM, Corentin Jabot via SG16 wrote:
>>
>>
>>
>> On Mon, Apr 26, 2021 at 6:19 PM Tom Honermann via SG16 <
>> sg16_at_[hidden]> wrote:
>>
>>> On 4/19/21 10:58 AM, Tom Honermann via SG16 wrote:
>>>
>>> SG16 will hold a telecon on Wednesday, April 28th at 19:30 UTC (timezone
>>> conversion
>>> <https://www.timeanddate.com/worldclock/converter.html?iso=20210428T193000&p1=1440&p2=tz_pdt&p3=tz_mdt&p4=tz_cdt&p5=tz_edt&p6=tz_cest>
>>> ).
>>>
>>> The agenda is:
>>>
>>> - P2093R5: Formatted output <https://wg21.link/p2093r5>
>>> - P2348R0: Whitespaces Wording Revamp
>>> <https://isocpp.org/files/papers/P2348R0.pdf>
>>>
>>> LEWG discussed P2093R5 at their 2021-04-06 telecon and decided to refer
>>> the paper back to SG16 for further discussion. LEWG meeting minutes are
>>> available here
>>> <https://wiki.edg.com/bin/view/Wg21telecons2021/P2093#Library-Evolution-2021-04-06>;
>>> please review them prior to the telecon. LEWG reviewed the list of prior
>>> SG16 deferred questions posted to them here
>>> <http://lists.isocpp.org/lib-ext/2021/03/18189.php>. Of those, they
>>> established consensus on an answer for #2 (they agreed not to block
>>> std::print() on a proposal for underlying terminal facilities), but
>>> referred the rest back to us. My interpretation of their actions is that
>>> LEWG would like a revision of the paper to address these concerns based on
>>> SG16 input (e.g., discuss design options and SG16 consensus or lack
>>> thereof). We'll therefore focus on these questions at this telecon.
>>>
>>> Hubert provided the following very interesting example usage.
>>>
>>> std::print("{:%r}\n",
>>> std::chrono::system_clock::now().time_since_epoch());
>>>
>>> At issue is the encoding used by locale sensitive chrono formatters.
>>> Search [time.format] <http://eel.is/c++draft/time.format> for "locale"
>>> to find example chrono format specifiers that are locale dependent. The
>>> example above contains the %r specifier and is locale sensitive because
>>> AM/PM designations may be localized. In a Chinese locale the desired
>>> translation of "PM" is "下午", but the locale will provide the translation in
>>> the locale encoding. As specified in P2093R5, if the execution (literal)
>>> encoding is UTF-8, than std::print() will expect the translation to be
>>> provided in UTF-8, but if the locale is not UTF-8-based (e.g., Big5;
>>> perhaps Shift-JIS for the Japanese 午後 translation), then the result is
>>> mojibake. This is a good example of how locale conflates translation and
>>> character encoding.
>>>
>>> Addressing the above will be our first order of business. Please
>>> reserve some time to independently think about this problem (ignore
>>> responses to this message for a few days if you need to). I am explicitly
>>> not listing possible approaches to address this concern in this message so
>>> as to avoid adding (further) bias in any specific direction. I suspect the
>>> answers to the previously deferred SG16 questions will be easier to answer
>>> once this concern is resolved.
>>>
>>> Now that we've all had some time to think about this issue, here are
>>> some possible directions we can pursue to resolve it. These are presented
>>> in no particular order.
>>>
>>> - Specialize std::locale facets
>>> <https://en.cppreference.com/w/cpp/locale/locale> and related I/O
>>> manipulators like std::put_time()
>>> <https://en.cppreference.com/w/cpp/io/manip/put_time> for char8_t.
>>> This would allow std::print() to, when the literal encoding is
>>> UTF-8, opt-in to use of the UTF-8/char8_t facets and I/O
>>> manipulators.
>>> - When the literal encoding is UTF-8, stipulate that running the
>>> program in a non-UTF-8 based locale is non-conforming. This would
>>> effectively require MSVC programmers to, when building code with the
>>> /utf-8 option, to also force selection of a UTF-8 code page via a
>>> manifest
>>> <https://docs.microsoft.com/en-us/windows/uwp/design/globalizing/use-utf8-code-page>
>>> and require use of Windows 10 build 1903 or later.
>>> - When the literal encoding is UTF-8, specify that non-UTF-8 based
>>> locale dependent translations be implicitly transcoded (such transcoding
>>> should never result in errors except perhaps for memory allocation
>>> failures).
>>> - Drop the special case handling for the literal encoding being
>>> UTF-8 and specify that, when bypassing a stream to write directly to the
>>> console, that the output be implicitly transcoded from the current locale
>>> dependent encoding (whatever it is) to the console encoding (UTF-8).
>>>
>>>
>> We have 2 things to explain to LEWG for print. And we do not need to
>> operate change to the design, just to explain things to them in a terms
>> they can understand (and they want to rely on our expertise which
>> implies consensus among ourselves)
>>
>> 1. It is always non-sense to interpret a string in encoding X when it is
>> in fact not.
>> 2. From there, if a string literal is in UTF-8, we HAVE to assume the
>> execution encoding is also utf-8. Why rely on the literal encoding and not
>> execution? it is resilient to call to setlocale and more efficient. Also,
>> format strings are likely to be literals.
>> 3. From there if that string is displayed on a
>> terminal/console/screen/tty, it is text. So it has to be rendered
>> correctly. On a specific system (windows) there is a way to enforce that.
>> Because windows has a separate mechanism for unicode display and console
>> handling that exists independently of the C++ execution encoding.
>> 4. "we have to assume" in 2. implies a precondition. That is true
>> REGARDLESS of utf-8 or not. in all cases the format string has to be
>> interpreted as text, which assumes it is valid in the execution encoding.
>> CF the Microsoft STL issue for braces in shift JS.
>> 5. This means that converting to UTF-16 on windows for the purpose of
>> console display is always valid (no ""transcosding"" error) within the
>> contract of the function, and as such does not have to be specified.
>> Preconditions violations are UB within the standard library and we should
>> keep doing that. In practice the implementation (which is here the
>> terminal, not the stl) will do character replacement the best it can, or
>> render something horrible.
>>
>> I agree with all of that, but I don't see how it relates to the
>> problematic example above. The issue with the example is that the "%r"
>> field specifier may cause non-UTF-8 content supplied by the locale to be
>> written.
>>
> I see two problems here.
> One is that this should not be locale dependent by default - has that been
> discussed? It seems to run amok of fmt design.
>
> The other is that, if print("xxx{}", foo) assumes that xxx is utf8, and
> the formated result is displayed onto a terminal, then the entire thing
> _has to_ be utf-8. note that this is because of
> a precondition on the act if displaying on the terminal which has nothing
> to do with formatting it's a 2 step process format -> print on terminal
> both of which have different preconditions (formating puts a requirement on
> the format string, to parse it, print additionally puts preconditions that
> the resulting thing will be utf8 such that individual arguments have to be
> to.
>
>
>>
>> The locale in there is a red herring. Changing the execution encoding is
>> always dicey - all strings that were correctly interpreted correctly
>> before the locale change are potentially no longer
>> correctly interpreted because their encoding no longer matches the new
>> execution encoding.
>> The existence of a setlocale function doesn't imply that calling it leads
>> to sensible results if the locale change also changes the encoding :)
>>
>> The example doesn't assume a locale change, at least not beyond an
>> initial std::setlocale(LC_ALL, "") during program startup.
>>
>>
>>
>> > Specialize std::locale facets
>> <https://en.cppreference.com/w/cpp/locale/locale> and related I/O
>> manipulators like std::put_time()
>> <https://en.cppreference.com/w/cpp/io/manip/put_time> for char8_t. This
>> would allow std::print() to, when the literal encoding is UTF-8, opt-in
>> to use of the UTF-8/char8_t facets and I/O manipulators.
>>
>> This is a different issue, one Peter and I have discussed. we should not
>> try to shove char into char8_t. Both char8_t and utf-8 char are valid use
>> cases. Also, the whole point of fmt::print is to avoid all of that :)
>>
>> I think this is strongly related, or we are misunderstanding each other.
>> I see the point of std::print() being to bypass the implicit (wrong)
>> console transcoding.
>>
> fmt::print just dumps the bytes in the general case, similarly to printf,
> that is then interpreted incorrectly by the windows console. I don't see
> where there might be transcoding
> in the program (I expect the console to do interesting things, but that's
> outside of C++).
>
> C++ thinks a string is Utf-8
> System (incorrectly) disagrees
> System has a method that allows it to agree
> Do we use that method?
>
> I strongly agree that char8_t and UTF-8 char are valid use cases.
>>
>>
>> > When the literal encoding is UTF-8, stipulate that running the program
>> in a non-UTF-8 based locale is non-conforming. This would effectively
>> require MSVC programmers to, when building code with the /utf-8 option,
>> to also force selection of a UTF-8 code page via a manifest
>> <https://docs.microsoft.com/en-us/windows/uwp/design/globalizing/use-utf8-code-page>
>> and require use of Windows 10 build 1903 or later.
>>
>> If you program contains literals that are not correctly interpreted by
>> the execution encoding, the behavior of your program cannot be correct
>> <insert scary U word>. So they should probably do that but it seems out of
>> scope.
>> The literalS encoding and the execution encoding should be consistent
>> (each string literal should be correctly interpreted).
>>
>> > When the literal encoding is UTF-8, specify that non-UTF-8 based locale
>> dependent translations be implicitly transcoded
>> Sorry, can you detail what you mean? I do not understand, sorry
>>
>> In the example above, the "%r" field specifier indicates that a locale
>> dependent 12-hour clock time be formatted. The AM/PM designator to be
>> formatted is locale dependent. If the locale is not UTF-8 based, then
>> mojibake is produced (if the literal encoding is UTF-8). This suggestion
>> addresses the problem by implicitly transcoding the locale dependent AM/PM
>> designator from the locale encoding to UTF-8 when formatting the output.
>>
>
> Think about cases in which that can happen
> There is a non-utf8 locale and a utf8 string literal mixed together.
>
>
>>
>> > Drop the special case handling for the literal encoding being UTF-8 and
>> specify that, when bypassing a stream to write directly to the console,
>> that the output be implicitly transcoded from the current locale dependent
>> encoding (whatever it is) to the console encoding (UTF-8).
>>
>> Dropping the special case seems more difficult in terms of wording.
>>
>> I think it is simpler actually; we would just have to say that the
>> implicit transcoding is from the locale encoding to the console encoding.
>>
>
> It's really hard to know what the console encoding is (it is a very
> microsoft specific thing), and the windows console basically have a wide
> (utf16) and narrow encoding (not sure it works exactly like that but it's a
> good enough model)
> Transcoding in the general case might be worse.
> A wording that encourages vendors to... encourage utf8 content to not be
> misinterpreted as something else might help but good luck wording that!
> Especially as it needs to handle file redirection, etc
>
>
>> If everything else fails, Microsoft could do the sensible thing as a
>> matter of QOL.
>>
>> Agreed.
>>
>> Tom.
>>
>>
>>
>>
>>> Please feel free to comment on these, or additional, approaches before
>>> our meeting on Wednesday.
>>>
>>> I think it would benefit LEWG if a revision of the paper presented each
>>> of these possibilities, the consequences, and the rationale (and hopefully
>>> SG16 consensus) for the proposed direction.
>>>
>>> Tom.
>>>
>>> I do not intend to time limit discussion of P2093R5 as I believe this is
>>> an important matter to resolve. If we are able to complete discussion of
>>> P2093R5, then we'll discuss P2348R0.
>>>
>>> Tom.
>>>
>>>
>>> --
>>> SG16 mailing list
>>> SG16_at_[hidden]
>>> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>>>
>>
>>
>>
Received on 2021-04-27 04:32:54