Date: Sun, 14 Mar 2021 14:12:28 -0700
On Sunday, 14 March 2021 11:08:16 PDT Hubert Tong via SG16 wrote:
> None that I am aware of in particular. However, extending terminfo, etc. so
> that such an interface becomes available in the future could not be
> discounted as a possibility.
Already done, 20 years ago. See
https://en.wikipedia.org/wiki/ISO/
IEC_2022#Interaction_with_other_coding_systems
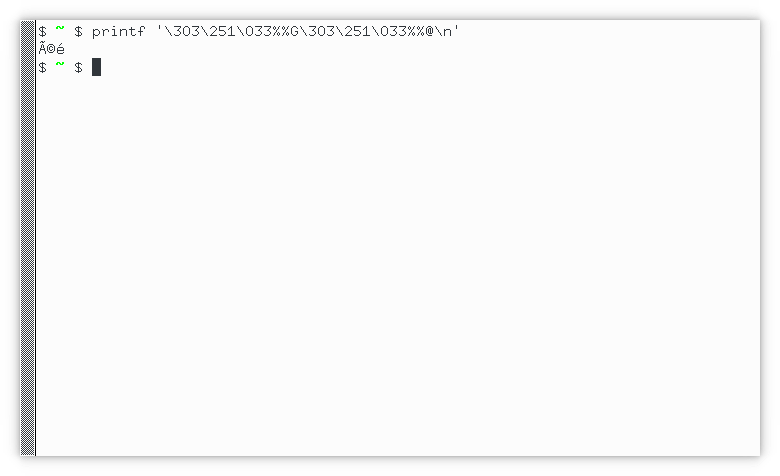
printf '\033%%G\303\251\033%%@\n'
Will show "é" in any half-decent terminal (including the Linux virtual
console, but apparently not the FreeBSD one), regardless of its own internal
encoding. See this screenshot from xterm, started with LC_ALL=C.
> None that I am aware of in particular. However, extending terminfo, etc. so
> that such an interface becomes available in the future could not be
> discounted as a possibility.
Already done, 20 years ago. See
https://en.wikipedia.org/wiki/ISO/
IEC_2022#Interaction_with_other_coding_systems
printf '\033%%G\303\251\033%%@\n'
Will show "é" in any half-decent terminal (including the Linux virtual
console, but apparently not the FreeBSD one), regardless of its own internal
encoding. See this screenshot from xterm, started with LC_ALL=C.
-- Thiago Macieira - thiago (AT) macieira.info - thiago (AT) kde.org Software Architect - Intel DPG Cloud Engineering
Received on 2021-03-14 16:12:38