Date: Thu, 26 Nov 2020 11:56:46 -0800
Hi Tom,
Thanks for the detailed feedback.
> I agree with the default output stream being stdout as opposed to
std::cout or its associated std::streambuf. The former better preserves
compatibility with other stream oriented formatting facilities; the latter
two suffer from private buffering, localization, and conversion services
(such services must be integrated or synchronized at a lower level in order
for multiple formatting facilities to coexist peacefully).
Good points, I'll add them in the next revision of the paper.
> it is not at all clear to me how that could be done correctly for wide
C++ streams
AFAICS wide streams are virtually unused nowadays. For example codesearch
gives 114 matches for fwide (
https://codesearch.isocpp.org/cgi-bin/cgi_ppsearch?q=fwide&search=Search)
and those are mostly in standard library implementations. In any case, I
think this belongs in a separate paper.
> The paper notes that P1885 <https://wg21.link/p1885> would provide an
improvement over the is_utf8() method of encoding determination. I agree,
but there are multiple ways in which it could be used to provide
improvements and I'm not sure which capabilities Victor has in mind ...
I was referring to detecting literal encoding as shown in your example.
Runtime system encoding detection would be a wrong thing to do for reasons
explained in the paper (and elaborated below). I will clarify this in the
next revision.
> The desired behavior for #2 is less clear.
I think it's clear that the encoding should be UTF-8 in this case because
using legacy CP1251 would cause loss of data and won't solve mojibake as
I'll demonstrate below. Note that CP1251 is hardly ever used as a file
encoding even on Windows - I know this because I actually was a Russian
Windows user in the past. For example, usage of this encoding for websites
dropped from 4.3% to 0.9% in the last 10 years (
https://w3techs.com/technologies/history_overview/character_encoding/ms/y)
and continues to drop. Putting aside the web, if you look at a Windows
application that works with text such as Notepad, you'll notice that even
with Russian localization UTF-8 is the default:
[image: image.png]
Notepad doesn't even list CP1251 explicitly as an encoding option! You can
specify the "ANSI" encoding which will give you CP1251 if you happen to run
Windows in Russian (or another language where CP1251 is the default
codepage). However, this won't be compatible with the terminal encoding
which is CP866 (https://en.wikipedia.org/wiki/Code_page_866). So if you try
to display a file written in CP1251 in a terminal (or a Windows system with
the different codepage) you'll get mojibake:
[image: image.png]
You would also pay a performance penalty of transcoding to make this data
loss and mojibake possible.
While it is clear that #2 should be UTF-8, #3 is slightly less obvious.
However there are two observations here:
1. We won't solve the mojibake problem by switching from UTF-8 to CP1251.
2. Most files are already in UTF-8 so the interoperability with programs
using legacy codepages is already there, e.g. you'll get the same problem
if you do `grep test.txt`.
I think the best we can do in #3 is to be consistent with common
application defaults and use UTF-8 when the user asks for it (with /utf8 or
some other mechanism) and not try doing a magic transcoding since the
latter won't work anyway and will only cause the data loss and performance
penalty.
> To make that last point a bit more concrete, consider the greet | grep
"Привет" example above. If greet produces UTF-8 in a Windows-1251
environment, then a user will have to explicitly deal with the encoding
differences,
Unfortunately your example won't work with CP1251 either:
[image: image.png]
(I used findstr since grep is uncommon in Windows but the idea is the same.)
> Some other nit-picky items
I'll address them in the next revision, thanks!
Cheers,
Victor
On Sun, Nov 22, 2020 at 9:33 PM Tom Honermann via SG16 <
sg16_at_[hidden]> wrote:
> SG16 began reviewing P2093R2 <https://wg21.link/p2093r2> in our recent
> telecon <https://github.com/sg16-unicode/sg16-meetings#november-11th-2020>
> and will continue review in our next telecon scheduled for December 9th.
>
> The following reflects my personal thoughts on this proposal.
>
> First, I'm excited by this proposal as I think it presents an opportunity
> to correct for some mistakes made in the past. In particular, this is a
> chance to get character encoding right such that, for the first time, C++
> code like the following could be written simply and portably (well, almost,
> use of universal-character-names will be required until UTF-8 encoded
> source files are truly portable; efforts are under way):
>
> int main() {
> std::print("👋 🌎"); // Hello world in the universal language of emoji (
> U+1F44B U+1F30E)
> }
>
> (and yes, I know our mail list archives will mess up the encoding; that is
> another battle for another day)
>
> I agree with the default output stream being stdout as opposed to
> std::cout or its associated std::streambuf. The former better preserves
> compatibility with other stream oriented formatting facilities; the latter
> two suffer from private buffering, localization, and conversion services
> (such services must be integrated or synchronized at a lower level in order
> for multiple formatting facilities to coexist peacefully). It is clear to
> me how the proposed interface can be extended to support wchar_t, char8_t,
> char16_t, and char32_t in the future if output is written directly to a C
> (or POSIX) stream, but it is not at all clear to me how that could be done
> correctly for wide C++ streams; char has won when it comes to I/O
> interfaces and there is no expectation of that changing any time soon.
>
> The paper notes that P1885 <https://wg21.link/p1885> would provide an
> improvement over the is_utf8() method of encoding determination. I
> agree, but there are multiple ways in which it could be used to provide
> improvements and I'm not sure which capabilities Victor has in mind (we
> haven't discussed this in SG16 yet). It could be used as a simple
> replacement for the is_utf() implementation. For example:
>
> constexpr bool is_utf8() {
> return text_encoding::literal() ==
> text_encoding(text_encoding::id::UTF8);
> }
>
> However, P1885 could also be used to detect the system (run-time) encoding
> such that output could then be transcoded to match. This is the
> possibility I alluded to above about this being an opportunity to get
> character encoding right.
> Consider the following program invocations in a Russian Windows
> environment with a default code page of Windows-1251 where greet is a C++
> program compiled so that the execution encoding is UTF-8 (e.g., via the
> Visual C++ /utf-8 option) and where it writes the Russian greeting (to a
> Greek friend) example from the paper, std::print("Привет, κόσμος!").
>
> # An invocation that writes to the console.
> > greet #1
>
> # An invocation that writes to a file.
> > greet > file.txt #2
>
> # An invocation that writes to a pipe.
> > greet | grep "Привет" #3
>
> The desired behavior for #1 is clear; regardless of the system (run-time)
> encoding, the goal is for the console to display the intended characters.
> The execution encoding is known. If the console encoding is also known or
> can be specified, then getting this right is a straight forward case of
> transcoding to the desired encoding.
>
> The desired behavior for #2 is less clear. The Reasonable encoding
> options are UTF-8 and Windows-1251. Both are reasonable options, but the
> latter will not be able to represent the full output accurately as some of
> the Greek characters are not available in Windows-1251 and will therefore
> be substituted in some way. But if UTF-8 is produced and the next program
> that reads the file consumes it as Windows-1251, then the accuracy provided
> by UTF-8 won't matter anyway. Only the user is in a position of knowing
> what the desired outcome is.
>
> The desired behavior for #3 is more clear. For grep to work as intended,
> the encoding of the input and the pattern must match or both converted to a
> common encoding. In the absence of explicit direction, grep must assume
> that the input and pattern are both encoded as Windows-1251. Assuming
> UTF-8 is not an option because the command line used for the invocation
> (that contains the pattern) is Windows-1251 encoded.
>
> Reliable and standard interfaces exist to determine when a stream is
> directed to a terminal/console; POSIX specifies isatty()
> <https://pubs.opengroup.org/onlinepubs/009695399/functions/isatty.html>
> as noted in the paper. It is generally possible to determine if a stream
> corresponds to a file or a pipe as well, but that isn't the extent of
> stream types that exist. There are also sockets, FIFOs, and other
> arbitrary character devices. I believe it is reasonable to differentiate
> behavior for a terminal/console, but I think attempting to differentiate
> behavior for other kinds of streams would be a recipe for surprising and
> difficult to explain behavior.
>
> The approach taken in the paper is, if writing to a Unicode capable
> terminal/console and the literal (execution) encoding is UTF-8, then use
> native interfaces as necessary to ensure the correct characters appear on
> the console; otherwise, just write the characters to the stream. This
> suffices to address #1 above (for the specific case of UTF-8), but it
> doesn't help with other encodings, nor does it help to improve the
> situation for #2 or #3.
>
> The model that I believe produces the least surprises and is therefore the
> easiest to use reliably is one in which a program uses whatever internal
> encoding its programmers prefer (one can think of the execution/literal
> encoding as the internal encoding) and then transcodes to the
> system/run-time encoding on I/O boundaries. Thus, a program that uses
> UTF-8 as the execution/literal encoding would produce Windows-1251 output
> in the non-terminal/console scenarios described above. This differs from
> the model described in the paper (UTF-8 output would be produced in that
> model).
>
> I expect some people reading this to take the position that if it isn't
> UTF-8 then it is wrong. My response is that mojibake is even more wrong.
> The unfortunate reality is that there are several important ecosystems that
> are not yet, and may never be, able to migrate to UTF-8 as the
> system/run-time encoding. Maintaining a clear separation between internal
> encoding and external encoding enables correct behavior without having to
> recompile programs to choose a different literal/execution encoding. As
> existing ecosystems migrate their system/run-time encoding to UTF-8,
> programs written in this way will transparently migrate with them.
>
> To make that last point a bit more concrete, consider the greet | grep
> "Привет" example above. If greet produces UTF-8 in a Windows-1251
> environment, then a user will have to explicitly deal with the encoding
> differences, perhaps by inserting a conversion operation as in greet |
> iconv -f utf-8 -t windows-1251 | grep "Привет". The problem with this
> is, if the system/run-time encoding changes in the future, then the
> explicit conversion will introduce mojibake. Thus, such workarounds become
> an impediment to UTF-8 migration.
>
> The behavior I want to see adopted for std::print() is:
>
> 1. When writing directly to a terminal/console, exploit native
> interfaces as necessary for text to be displayed correctly.
> 2. Otherwise, write output encoded to match the system/run-time
> encoding; the encoding that P1885 indicates via text_encoding::system()
> .
>
> Some other nit-picky items:
>
> - Section 6, "Unicode" states that the vprint_unicode() function is
> exposition-only, but it and vprint_nonunicode() are both present in
> the proposed wording with no indication of being exposition-only.
> - Section 6, "Unicode" discusses use of the Visual C++ /utf-8 option.
> This section is incorrect in stating that both the source and literal
> (execution) encoding must be UTF-8 for is_utf8() to return true; the
> source encoding is not relevant. Only the /execution-charset:utf-8
> option is needed (the /utf-8 option implies both /source-charset:utf-8
> and /execution-charset:utf-8).
> - It may be worth noting in the paper that overloads could
> additionally be provided to support writing directly to POSIX file
> descriptors as is done by the POSIX dprintf() interface
> <https://pubs.opengroup.org/onlinepubs/9699919799/functions/dprintf.html>
> (which can be quite useful to write directly to a socket, pipe, or file).
>
> Tom.
> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>
Thanks for the detailed feedback.
> I agree with the default output stream being stdout as opposed to
std::cout or its associated std::streambuf. The former better preserves
compatibility with other stream oriented formatting facilities; the latter
two suffer from private buffering, localization, and conversion services
(such services must be integrated or synchronized at a lower level in order
for multiple formatting facilities to coexist peacefully).
Good points, I'll add them in the next revision of the paper.
> it is not at all clear to me how that could be done correctly for wide
C++ streams
AFAICS wide streams are virtually unused nowadays. For example codesearch
gives 114 matches for fwide (
https://codesearch.isocpp.org/cgi-bin/cgi_ppsearch?q=fwide&search=Search)
and those are mostly in standard library implementations. In any case, I
think this belongs in a separate paper.
> The paper notes that P1885 <https://wg21.link/p1885> would provide an
improvement over the is_utf8() method of encoding determination. I agree,
but there are multiple ways in which it could be used to provide
improvements and I'm not sure which capabilities Victor has in mind ...
I was referring to detecting literal encoding as shown in your example.
Runtime system encoding detection would be a wrong thing to do for reasons
explained in the paper (and elaborated below). I will clarify this in the
next revision.
> The desired behavior for #2 is less clear.
I think it's clear that the encoding should be UTF-8 in this case because
using legacy CP1251 would cause loss of data and won't solve mojibake as
I'll demonstrate below. Note that CP1251 is hardly ever used as a file
encoding even on Windows - I know this because I actually was a Russian
Windows user in the past. For example, usage of this encoding for websites
dropped from 4.3% to 0.9% in the last 10 years (
https://w3techs.com/technologies/history_overview/character_encoding/ms/y)
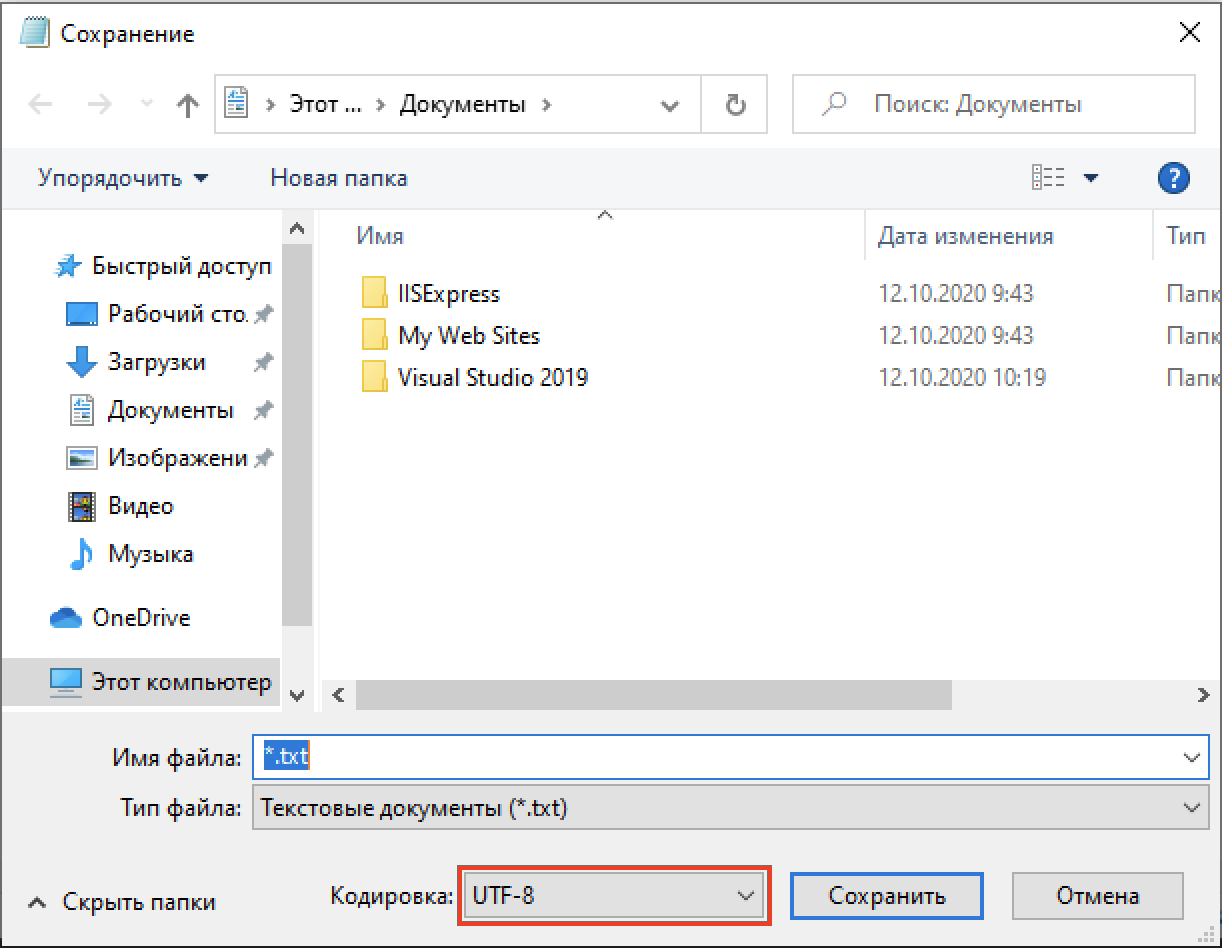
and continues to drop. Putting aside the web, if you look at a Windows
application that works with text such as Notepad, you'll notice that even
with Russian localization UTF-8 is the default:
[image: image.png]
Notepad doesn't even list CP1251 explicitly as an encoding option! You can
specify the "ANSI" encoding which will give you CP1251 if you happen to run
Windows in Russian (or another language where CP1251 is the default
codepage). However, this won't be compatible with the terminal encoding
which is CP866 (https://en.wikipedia.org/wiki/Code_page_866). So if you try
to display a file written in CP1251 in a terminal (or a Windows system with
the different codepage) you'll get mojibake:
[image: image.png]
You would also pay a performance penalty of transcoding to make this data
loss and mojibake possible.
While it is clear that #2 should be UTF-8, #3 is slightly less obvious.
However there are two observations here:
1. We won't solve the mojibake problem by switching from UTF-8 to CP1251.
2. Most files are already in UTF-8 so the interoperability with programs
using legacy codepages is already there, e.g. you'll get the same problem
if you do `grep test.txt`.
I think the best we can do in #3 is to be consistent with common
application defaults and use UTF-8 when the user asks for it (with /utf8 or
some other mechanism) and not try doing a magic transcoding since the
latter won't work anyway and will only cause the data loss and performance
penalty.
> To make that last point a bit more concrete, consider the greet | grep
"Привет" example above. If greet produces UTF-8 in a Windows-1251
environment, then a user will have to explicitly deal with the encoding
differences,
Unfortunately your example won't work with CP1251 either:
[image: image.png]
(I used findstr since grep is uncommon in Windows but the idea is the same.)
> Some other nit-picky items
I'll address them in the next revision, thanks!
Cheers,
Victor
On Sun, Nov 22, 2020 at 9:33 PM Tom Honermann via SG16 <
sg16_at_[hidden]> wrote:
> SG16 began reviewing P2093R2 <https://wg21.link/p2093r2> in our recent
> telecon <https://github.com/sg16-unicode/sg16-meetings#november-11th-2020>
> and will continue review in our next telecon scheduled for December 9th.
>
> The following reflects my personal thoughts on this proposal.
>
> First, I'm excited by this proposal as I think it presents an opportunity
> to correct for some mistakes made in the past. In particular, this is a
> chance to get character encoding right such that, for the first time, C++
> code like the following could be written simply and portably (well, almost,
> use of universal-character-names will be required until UTF-8 encoded
> source files are truly portable; efforts are under way):
>
> int main() {
> std::print("👋 🌎"); // Hello world in the universal language of emoji (
> U+1F44B U+1F30E)
> }
>
> (and yes, I know our mail list archives will mess up the encoding; that is
> another battle for another day)
>
> I agree with the default output stream being stdout as opposed to
> std::cout or its associated std::streambuf. The former better preserves
> compatibility with other stream oriented formatting facilities; the latter
> two suffer from private buffering, localization, and conversion services
> (such services must be integrated or synchronized at a lower level in order
> for multiple formatting facilities to coexist peacefully). It is clear to
> me how the proposed interface can be extended to support wchar_t, char8_t,
> char16_t, and char32_t in the future if output is written directly to a C
> (or POSIX) stream, but it is not at all clear to me how that could be done
> correctly for wide C++ streams; char has won when it comes to I/O
> interfaces and there is no expectation of that changing any time soon.
>
> The paper notes that P1885 <https://wg21.link/p1885> would provide an
> improvement over the is_utf8() method of encoding determination. I
> agree, but there are multiple ways in which it could be used to provide
> improvements and I'm not sure which capabilities Victor has in mind (we
> haven't discussed this in SG16 yet). It could be used as a simple
> replacement for the is_utf() implementation. For example:
>
> constexpr bool is_utf8() {
> return text_encoding::literal() ==
> text_encoding(text_encoding::id::UTF8);
> }
>
> However, P1885 could also be used to detect the system (run-time) encoding
> such that output could then be transcoded to match. This is the
> possibility I alluded to above about this being an opportunity to get
> character encoding right.
> Consider the following program invocations in a Russian Windows
> environment with a default code page of Windows-1251 where greet is a C++
> program compiled so that the execution encoding is UTF-8 (e.g., via the
> Visual C++ /utf-8 option) and where it writes the Russian greeting (to a
> Greek friend) example from the paper, std::print("Привет, κόσμος!").
>
> # An invocation that writes to the console.
> > greet #1
>
> # An invocation that writes to a file.
> > greet > file.txt #2
>
> # An invocation that writes to a pipe.
> > greet | grep "Привет" #3
>
> The desired behavior for #1 is clear; regardless of the system (run-time)
> encoding, the goal is for the console to display the intended characters.
> The execution encoding is known. If the console encoding is also known or
> can be specified, then getting this right is a straight forward case of
> transcoding to the desired encoding.
>
> The desired behavior for #2 is less clear. The Reasonable encoding
> options are UTF-8 and Windows-1251. Both are reasonable options, but the
> latter will not be able to represent the full output accurately as some of
> the Greek characters are not available in Windows-1251 and will therefore
> be substituted in some way. But if UTF-8 is produced and the next program
> that reads the file consumes it as Windows-1251, then the accuracy provided
> by UTF-8 won't matter anyway. Only the user is in a position of knowing
> what the desired outcome is.
>
> The desired behavior for #3 is more clear. For grep to work as intended,
> the encoding of the input and the pattern must match or both converted to a
> common encoding. In the absence of explicit direction, grep must assume
> that the input and pattern are both encoded as Windows-1251. Assuming
> UTF-8 is not an option because the command line used for the invocation
> (that contains the pattern) is Windows-1251 encoded.
>
> Reliable and standard interfaces exist to determine when a stream is
> directed to a terminal/console; POSIX specifies isatty()
> <https://pubs.opengroup.org/onlinepubs/009695399/functions/isatty.html>
> as noted in the paper. It is generally possible to determine if a stream
> corresponds to a file or a pipe as well, but that isn't the extent of
> stream types that exist. There are also sockets, FIFOs, and other
> arbitrary character devices. I believe it is reasonable to differentiate
> behavior for a terminal/console, but I think attempting to differentiate
> behavior for other kinds of streams would be a recipe for surprising and
> difficult to explain behavior.
>
> The approach taken in the paper is, if writing to a Unicode capable
> terminal/console and the literal (execution) encoding is UTF-8, then use
> native interfaces as necessary to ensure the correct characters appear on
> the console; otherwise, just write the characters to the stream. This
> suffices to address #1 above (for the specific case of UTF-8), but it
> doesn't help with other encodings, nor does it help to improve the
> situation for #2 or #3.
>
> The model that I believe produces the least surprises and is therefore the
> easiest to use reliably is one in which a program uses whatever internal
> encoding its programmers prefer (one can think of the execution/literal
> encoding as the internal encoding) and then transcodes to the
> system/run-time encoding on I/O boundaries. Thus, a program that uses
> UTF-8 as the execution/literal encoding would produce Windows-1251 output
> in the non-terminal/console scenarios described above. This differs from
> the model described in the paper (UTF-8 output would be produced in that
> model).
>
> I expect some people reading this to take the position that if it isn't
> UTF-8 then it is wrong. My response is that mojibake is even more wrong.
> The unfortunate reality is that there are several important ecosystems that
> are not yet, and may never be, able to migrate to UTF-8 as the
> system/run-time encoding. Maintaining a clear separation between internal
> encoding and external encoding enables correct behavior without having to
> recompile programs to choose a different literal/execution encoding. As
> existing ecosystems migrate their system/run-time encoding to UTF-8,
> programs written in this way will transparently migrate with them.
>
> To make that last point a bit more concrete, consider the greet | grep
> "Привет" example above. If greet produces UTF-8 in a Windows-1251
> environment, then a user will have to explicitly deal with the encoding
> differences, perhaps by inserting a conversion operation as in greet |
> iconv -f utf-8 -t windows-1251 | grep "Привет". The problem with this
> is, if the system/run-time encoding changes in the future, then the
> explicit conversion will introduce mojibake. Thus, such workarounds become
> an impediment to UTF-8 migration.
>
> The behavior I want to see adopted for std::print() is:
>
> 1. When writing directly to a terminal/console, exploit native
> interfaces as necessary for text to be displayed correctly.
> 2. Otherwise, write output encoded to match the system/run-time
> encoding; the encoding that P1885 indicates via text_encoding::system()
> .
>
> Some other nit-picky items:
>
> - Section 6, "Unicode" states that the vprint_unicode() function is
> exposition-only, but it and vprint_nonunicode() are both present in
> the proposed wording with no indication of being exposition-only.
> - Section 6, "Unicode" discusses use of the Visual C++ /utf-8 option.
> This section is incorrect in stating that both the source and literal
> (execution) encoding must be UTF-8 for is_utf8() to return true; the
> source encoding is not relevant. Only the /execution-charset:utf-8
> option is needed (the /utf-8 option implies both /source-charset:utf-8
> and /execution-charset:utf-8).
> - It may be worth noting in the paper that overloads could
> additionally be provided to support writing directly to POSIX file
> descriptors as is done by the POSIX dprintf() interface
> <https://pubs.opengroup.org/onlinepubs/9699919799/functions/dprintf.html>
> (which can be quite useful to write directly to a socket, pipe, or file).
>
> Tom.
> --
> SG16 mailing list
> SG16_at_[hidden]
> https://lists.isocpp.org/mailman/listinfo.cgi/sg16
>


Received on 2020-11-26 13:57:01